Verfügbarkeit: an sich recht einfach und und doch überraschend komplex
Dieser Artikel wurde auf der Grundlage eines Vortrags von Hans Maurer verfasst. Der Mitbegründer und ehemalige Mitarbeiter der amasol-Geschäftsführung ist heute selbständiger IT-Problemlöser und berät amasol weiterhin als externer Hauptberater.

Schlüsselzahlen und Berichtszeitraum
Warum ist "Verfügbarkeit" heute so wichtig?
Die Verfügbarkeit ist eine der zentralen Kennzahlen für die Qualität eines Systems oder von IT-Dienstleistungen. Denn Geschäftsprozesse wie Produktion oder Logistik sind ohne IT nicht mehr möglich und ein Systemausfall bringt oft das gesamte Unternehmen oder Teile davon zum Stillstand, was zu Produktionsausfällen und Umsatzverlusten führt.
Auch die Verfügbarkeit spielt bei der Bewertung einer IT-Abteilung eine Rolle. Als "IT-Dienstleister" ist sie dafür verantwortlich, dass die Systeme laufen. Und sie muss - wie externe IT-Dienstleister - nachweisen, dass die in Service Level Agreements (SLAs) festgelegten Verfügbarkeitsstufen eingehalten wurden, andernfalls muss sie begründen, warum dies nicht der Fall ist. Die Verfügbarkeit ist letztlich die Grundlage für die Abrechnung der bereitgestellten IT-Systeme und -Dienste.
Der Nachweis der Verfügbarkeit ist ein zentrales Thema bei der Zusammenarbeit zwischen internen und externen Dienstleistern und ihren Kunden.
Verfügbarkeit - was ist das?
Der Begriff ist leicht zu definieren. Laut Wikipedia ist "die Verfügbarkeit eines technischen Systems [...] die Wahrscheinlichkeit oder das Maß dafür, dass das System bestimmte Anforderungen zu einem bestimmten Zeitpunkt oder innerhalb eines vereinbarten Zeitrahmens erfüllt. [...] Sie ist ein Qualitätskriterium und eine Kennzahl eines Systems."
Für seine Berechnung ergibt sich daraus die Formel:
Verfügbarkeit = (Gesamtzeit - Ausfallzeit)/Gesamtzeit
Dieser wird als Prozentsatz berechnet:
Verfügbarkeit = (Gesamtzeit - Ausfallzeit)/Gesamtzeit × 100 %
Diese Berechnung der Verfügbarkeit ist weit verbreitet. Sie führt in der Regel zu Werten von über 99 %. Systeme, bei denen eine Verfügbarkeit von 99,99 % oder mehr erreicht wird, werden als "hochverfügbar" bezeichnet. Die Bedeutung dieser Kennzahlen in der Praxis wird durch die folgenden Beispiele verdeutlicht: Für ein System, das 12 Stunden am Tag, an 5 Wochentagen, 52 Wochen verfügbar sein soll, bedeutet eine Verfügbarkeit von 99 % eine maximale Ausfallzeit von 31,2 Stunden. Für ein System, das 24 Stunden am Tag, 365 Tage im Jahr verfügbar sein soll und eine Verfügbarkeit von 99,999% ("Five Nines") erreichen soll, kommt dagegen eine maximale Ausfallzeit von nur 5,26 Minuten in Frage - im ganzen Jahr!
Es gibt auch eine Reihe von alternativen Metriken, die weniger häufig vorkommen:
- Anzahl der einzelnen Ausfälle
- Maximale Dauer der einzelnen Ausfälle
- Kumulative Ausfallzeit
Diese Metriken kommen in Frage, wenn es sich um einen "Single Point of Failure" handelt, also die Komponente eines übergeordneten Systems, deren Ausfall den Ausfall des gesamten Systems verursacht. Anzahl und Dauer der Ausfälle spielen eine zentrale Rolle bei der Bewertung der Verfügbarkeit. So kann ein einziger Ausfall von einer Stunde Dauer eine andere Auswirkung - auf die Produktivität des Gesamtsystems - haben als 60 Ausfälle von je einer Minute Dauer.
Der Berichtszeitraum - zweite wichtige Metrik
Eine weitere Kennzahl ist der Berichtszeitraum, für den die Verfügbarkeit gemessen wird. Die Nutzung von Systemen oder Diensten wird in der Regel auf monatlicher Basis abgerechnet. Kürzere (pro Tag) oder längere (pro Quartal, pro Jahr) Zeiträume sind selten. Bei einem Single Point of Failure kann ein kurzer Berichtszeitraum in Betracht kommen. Im Bericht werden die Monatswerte mit ihrem Ziel oft durch eine grafische Darstellung der Tageswerte ergänzt. So kann der Kunde auch die Verteilung der Ausfallzeiten sehen. Ein längerer Zeitraum ist sinnvoll, wenn die Bedeutung des Systems geringer ist oder es selten genutzt wird. Ein gängiger Wert ist hier "Year to Date", die Berechnung der Verfügbarkeit im aktuellen Berichtsjahr bis zum aktuellen Datum.
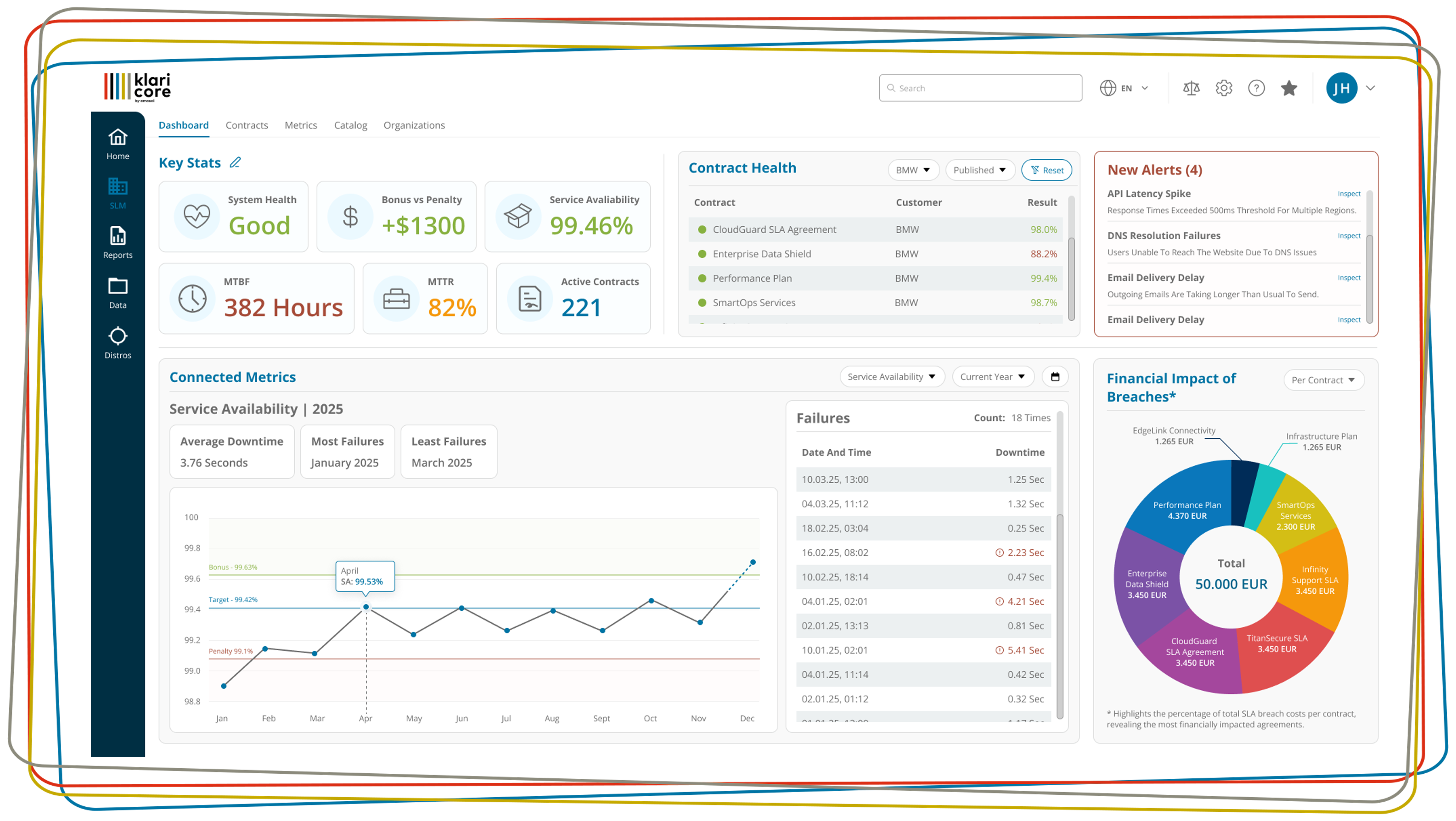
Datenquellen und Ergebnisse
Endgültige Ergebnisse oder detaillierte Daten
Daten und Messwerte zur Berechnung der Verfügbarkeit eines IT-Systems oder -Dienstes stammen meist aus zwei Quellen. Entweder werden "fertige" Werte in Prozenten geliefert oder es liegen Rohdaten zur Berechnung vor. Fertige Ergebnisse können manuell oder automatisch über ein Überwachungssystem erfasst werden. Die manuelle Methode ist für isolierte Systeme sinnvoll. In der Regel werden Monitoring-Tools verwendet. Allerdings verfügen nicht alle diese Tools über Datenschnittstellen zur automatischen Integration relevanter Daten. In diesem Fall ist ebenfalls ein manueller Aufwand erforderlich, um die aus verschiedenen Systemen gesammelten Messwerte zu einem plausiblen Endergebnis zu ergänzen.
Ein Sonderfall liegt vor, wenn ein IT-Dienstleister nicht nur eigene Leistungen erbringt, sondern auch Leistungen Dritter vermittelt. Wenn er als Generalunternehmer Service Level Agreements (SLAs) vereinbart hat, ist er dafür verantwortlich, dass seine Unterauftragnehmer die Leistungsdaten liefern, damit er als Vertragspartner die Verfügbarkeit des Systems nachweisen kann. Auch die Art der Ermittlung ist im Vertrag festgelegt. Dies kann zu Komplikationen führen, da die Methoden des "Zwischenhändlers" und die seiner Zulieferer festgelegt werden müssen. Darüber hinaus sollten alle Daten rechtzeitig eintreffen, damit die Berichte zum vereinbarten Zeitpunkt fertig sind.
Komponenten, Dienstleistungen, Tickets - Quellen für detaillierte Daten
Wenn ein Verfügbarkeitsbericht auf unternehmenseigenen Berechnungen beruht, stellt sich die Frage, auf welcher Grundlage die Daten erhoben werden. Die Zustands- oder Ausfalldaten von IT-Komponenten stammen oft aus den unterschiedlichsten Infrastrukturmanagementsystemen, in seltenen Fällen werden sie auch manuell erhoben. Die Erfassungsmethoden und die Formate, in denen die Daten aufbereitet werden, sind so unterschiedlich wie die Überwachungssysteme. Gängige Methoden sind die regelmäßige Aufzeichnung von Statuswerten, wie z.B. die Überprüfung der Verfügbarkeit im Minutentakt, oder die Auswertung von Ausfallzeitenlisten (Eventlogs). Auch die Verfügbarkeit pro Messintervall kann als Bewertungskriterium herangezogen werden. Sie gibt an, ob ein System oder eine Komponente in einem bestimmten Zeitraum kontinuierlich oder nur zeitweise (in Prozent) verfügbar war.
Aufgrund der zahlreichen unterschiedlichen Systeme, Methoden und Formate, die in der Regel zur Überwachung und Erfassung von Verfügbarkeitsdaten eingesetzt werden, müssen die Ergebnisse in ein definiertes Standardformat überführt werden. Nur so lässt sich eine valide und nachvollziehbare Aussage über die Gesamtverfügbarkeit treffen.
Detaillierte Daten für IT-Dienstleistungen
Anders sieht es aus, wenn es um die Erfassung detaillierter Daten für IT-Dienste wie E-Mail, CRM oder SAP geht. Bei solchen komplexen Diensten werden oft die Daten der einzelnen Teildienste zu einem Gesamtergebnis in Beziehung gesetzt. Hierfür gibt es verschiedene Methoden. Eine Möglichkeit ist der Single Point of Failure, bei dem der Ausfall einer Komponente den gesamten Dienst bedroht. Bei Systemen, in denen wesentliche Komponenten mehrfach verfügbar sind, ist die Redundanzmethode die beste Option. Verfügbarkeit wird angenommen, wenn mindestens eine der Komponenten verfügbar ist. Eine weitere Methode zur Korrelation der Komponentendetaildaten ist das Quorum. Es wird zum Beispiel bei Terminalserverfarmen eingesetzt. Hier kann per Definition bereits eine Verfügbarkeit bestehen, auch wenn die Hälfte der Server verfügbar ist.
Für die Berechnung des Gesamtergebnisses sind auch Korrelationsstrukturen wichtig. Dies können einfache, feste Strukturen sein, wie z. B. System - Cluster - Server - Prozess, die den Gesamtdienst darstellen.
Bei komplexeren Diensten wie SAP gibt es oft mehrere Dienstbäume mit Unterdiensten, die ihrerseits korrelierte Ergebnisse aus externen Datenquellen liefern.
Verfügbarkeitsdaten werden auch aus der Nutzerperspektive erhoben. Dazu werden Messwerte aus End-User-Experience-Management- oder Application-Performance-Management-Systemen verwendet. Diese führen über Monitoring-Agenten synthetische Messungen zur permanenten Erfassung von Vergleichswerten durch. Die Berechnungen erfolgen durch Aggregation von parallelen Messungen auf mehreren Clients zu einem Gesamtergebnis. Auch hier werden die beschriebenen Korrelationsverfahren zur Bewertung der Verfügbarkeit eingesetzt.
Real User Monitoring (RUM) zeichnet das Verhalten der aktiven Benutzer auf. Lücken entstehen z.B., wenn gerade niemand mit dem System arbeitet. Außerdem hängen die Messwerte vom individuellen Nutzerverhalten ab. Im Vergleich zur synthetischen Messung eignet sich RUM daher sehr gut für andere Messungen wie Abbruchraten oder den Anteil erfolgreicher Transaktionen.
Der Nutzer hat das Wort: Detaillierte Daten aus Support-Tickets
Eine weitere Möglichkeit der Verfügbarkeitsberechnung ist die Auswertung von automatisch oder manuell erstellten Incident-Tickets aus dem IT-Support oder User Help Desk. Bei der manuellen Bearbeitung müssen die einzelnen Tickets den jeweiligen Komponenten oder Services zugeordnet werden. Das ist nicht einfach, denn der Anwender meldet nur den Vorfall, der Servicemitarbeiter muss die betroffenen Komponenten und Services finden. Eine weitere Herausforderung ist die Zuordnung von Tickets zu Berichtszeiträumen, denn der Lebenszyklus eines Tickets kann sich über mehrere Wochen oder Monate erstrecken. Es muss klar sein, ob und wie offene Tickets in die Verfügbarkeitsberechnung einfließen. Darüber hinaus sollte definiert werden, ob Änderungen an aktiven Tickets rückwirkend auf die Ergebnisse eines bereits abgeschlossenen Berichtszeitraums wirken.
Versagen von Messgeräten: Mut, die Lücke zu schließen?
Es muss klar sein, wie mit Datenlücken umgegangen werden soll. Schließlich können jederzeit Messgeräte ausfallen oder Ergebnisse aus anderen technischen Gründen nicht verfügbar sein. Es muss entschieden werden, ob solche Lücken leistungsmäßig als "verfügbar", "nicht verfügbar" oder "nicht gemessen" gewertet werden und ob sie zu einer Verkürzung der Betriebszeit führen, was wiederum die Berechnung der Verfügbarkeit beeinflusst. Es sollte auch klar sein, ob eine Mindestlänge der einzelnen Ausfälle bei der Berechnung eine Rolle spielt. So könnten beispielsweise Ausfälle unter einer bestimmten Länge nicht berücksichtigt werden.
Es gibt eine Vielzahl von Datenquellen sowie Methoden und Formaten, die für die Verfügbarkeitsberechnung gewählt werden können. Um jedoch eine valide Aussage über die Verfügbarkeit des IT-Systems oder IT-Dienstes treffen zu können, müssen diese Daten einvernehmlich korreliert und in ein Standardformat umgewandelt werden
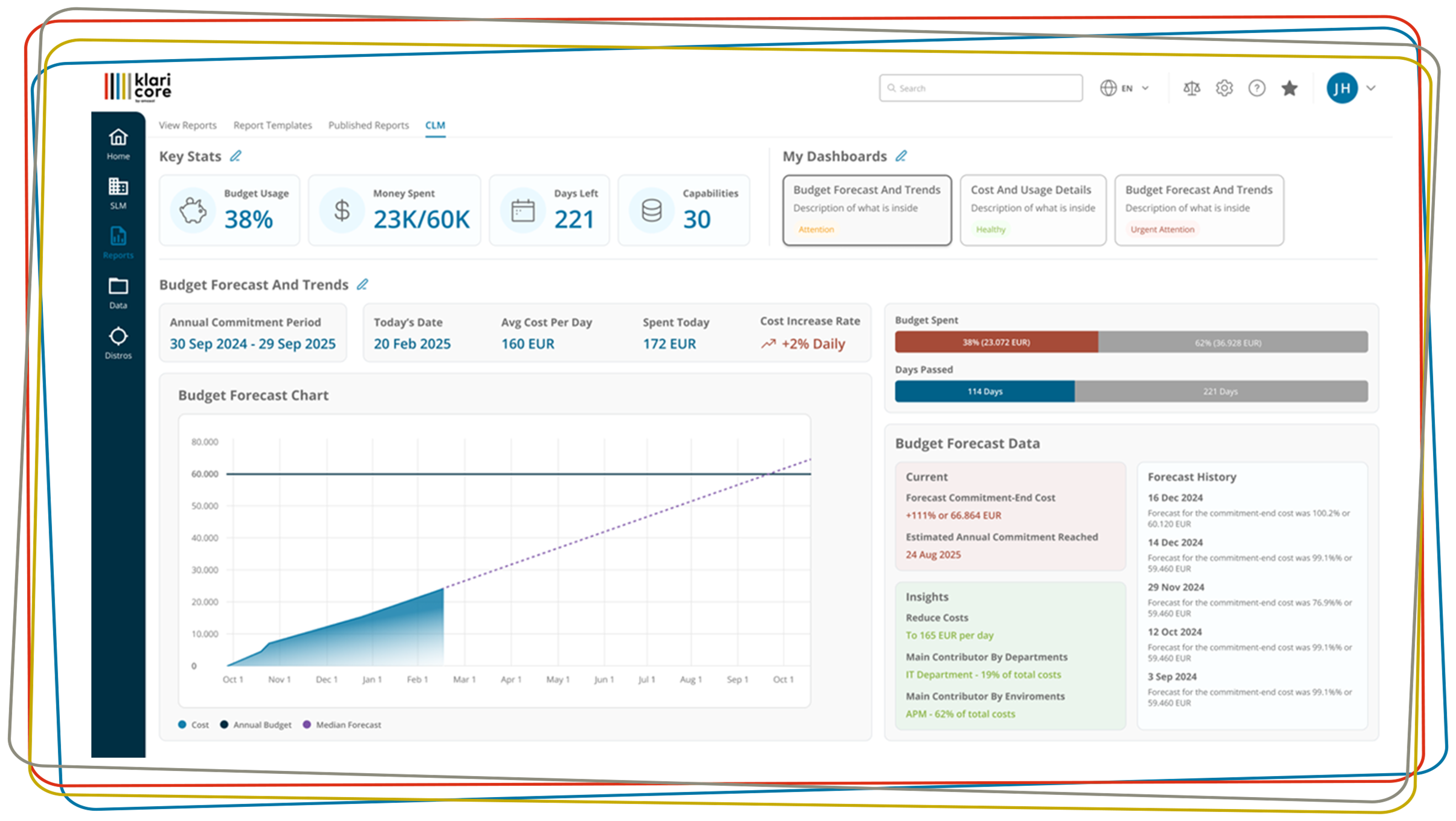
Verfügbarkeit: an sich einfach, aber erstaunlich komplex
Der Titel dieses Artikels wurde mit Bedacht gewählt. Einerseits glaubt jeder zu wissen, was der Begriff "Verfügbarkeit" bedeutet. Andererseits stellt sich in der Praxis oft erst heraus, dass die Formel "Verfügbarkeit = (Gesamtzeit - Ausfallzeit)/Gesamtzeit" allein ist nicht genug. Wie die praktische Erfahrung von amasol zeigt, steckt der Teufel oft im Detail.
So ist es nicht verwunderlich, dass es eine Vielzahl von Regelungen, Datenquellen, Messmethoden, Darstellungsformen und Verfahren zur Erstellung von Berichten gibt. Die Vertragspartner müssen sich darauf einigen, wer was, wann und wo misst und aufzeichnet, denn nur so entstehen valide Daten, die sicherstellen, dass gemeinsame Maßnahmen ergriffen werden können, um die Verfügbarkeit von IT-Systemen und -Diensten langfristig zu optimieren.
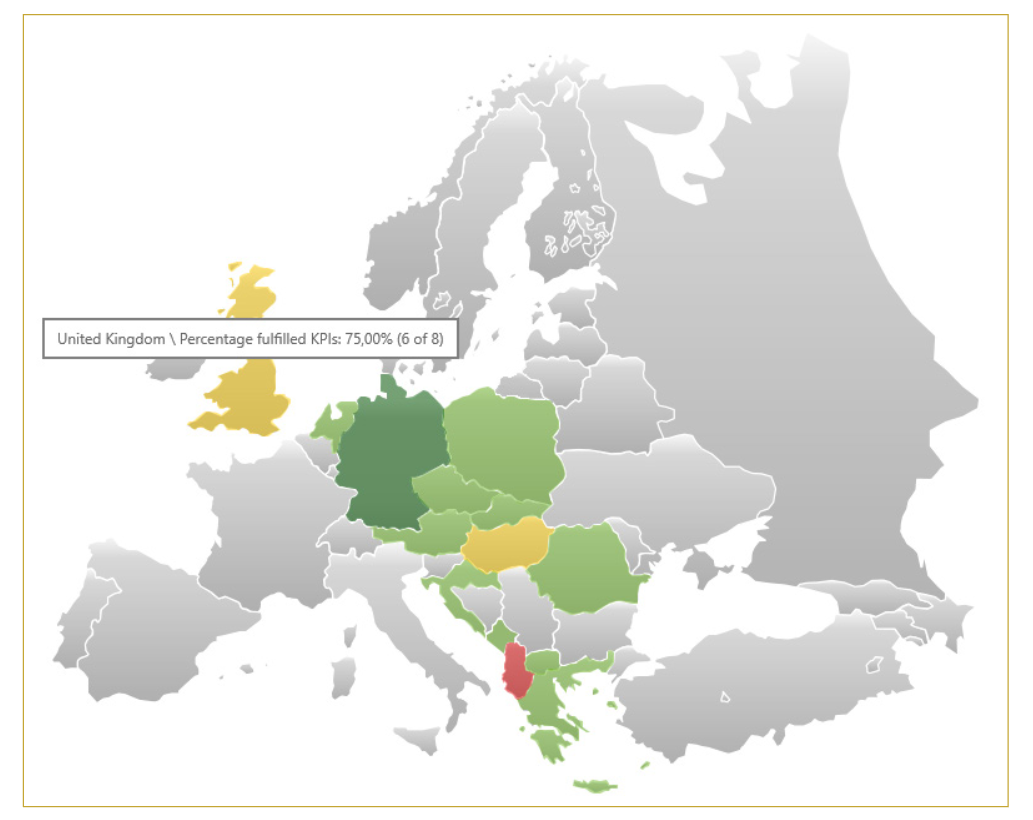
Korrekturen und Kommentare
Nachträgliche Korrektur und Kommentierung der Ergebnisse
Sobald die konsolidierten Ergebnisse zur Verfügbarkeit vorliegen, kann es notwendig sein, Korrekturen vorzunehmen. In der Regel werden die Werte nochmals überprüft, wenn ein (vermeintlich zu) unerwartetes Ergebnis errechnet wurde - das unter dem im SLA vereinbarten Ziel liegt. Es ist auch notwendig, die Zahlen zu kommentieren, insbesondere dann, wenn auch Korrekturen nicht zu einem besseren Ergebnis führen.
Am Endergebnis und an den detaillierten Daten sind gravierende Korrekturen möglich - sowohl vor als auch nach ihrer Normalisierung. In welcher Phase des Normalisierungs- und Berechnungsprozesses Korrekturen vorgenommen werden, ist von Projekt zu Projekt unterschiedlich. Generell ist es jedoch sinnvoll, sich auf ein Verfahren festzulegen, da der Korrekturprozess sonst unübersichtlich und nicht transparent wird.
Die beste Methode ist die manuelle Korrektur. Diese erfolgt durch den Leistungserbringer oder die Fachabteilung, das Servicemanagement, das Verfügbarkeitsmanagement oder das Kundenmanagement. Die für die Systeme verantwortliche Person oder Abteilung sollte die Ergebnisse auch auswerten. Oft ist dies nicht möglich. Dann findet der Prozess in einem abteilungs- oder unternehmensübergreifenden Team statt. Es ist sehr wichtig, dass der Input gesammelt, gemeinsam diskutiert, bewertet und schließlich freigegeben wird. Das gilt für Korrekturen und Kommentare.
Eine automatisierte Korrekturmethode besteht in der Auswertung von Change- oder Incident-Tickets sowie von Listen mit Wartungsintervallen. So sind beispielsweise Systemausfälle bei laufenden Änderungen für die Berechnung der Verfügbarkeit nicht relevant und müssen herausgerechnet werden. Die Vorfälle müssen den entsprechenden Komponenten, Services und Verträgen korrekt zugeordnet werden.
Die Auswirkungen der Korrekturen auf die Berechnung der Verfügbarkeit sind unterschiedlich. Auf diese Weise können Ausfallzeiten reduziert werden, was sich positiv auf das Ergebnis auswirkt. Manchmal ist es notwendig, Ausfälle in einzelne berechnungsrelevante und nicht berechnungsrelevante Phasen zu unterteilen, z.B. wenn sich ein Ausfall über den vereinbarten Änderungszeitraum hinaus erstreckt. Es ist möglich, dass Korrekturen zu einer Verkürzung der Betriebszeit führen, was sich ebenfalls auf das Endergebnis auswirken kann.
Mehrdimensionale Sicht durch Verdichtung der Einzelergebnisse
Die Menge der monatlich erfassten Berichtsdaten hat inzwischen ein Ausmaß erreicht, das eine Auswertung aller Daten fast unmöglich macht. Außerdem bevorzugt das Management in der Regel ein einfaches Ampelsystem. Eine seriöse Zusammenfassung der Ergebnisse muss daher einen schnellen Überblick über die aktuelle Situation und die Möglichkeit bieten, in kritischen Fällen auf tiefere Verdichtungsebenen vorzudringen.
Die Verdichtung der Einzelergebnisse erfolgt entlang verschiedener Hierarchien:
- Vom Service Level Objective (SLO) zum kompletten Vertrag
- Entlang der technischen Strukturen (IT-Systeme, Dienstleistungen)
- Entlang geografischer oder organisatorischer Strukturen (Standorte, Abteilungen, Kunden usw.)
Methodisch kann die Zusammenfassung durch die Berechnung gewichteter Durchschnittswerte erfolgen. Eine andere Möglichkeit ist die Berechnung der Anzahl der verletzten oder erfüllten SLOs. Natürlich ist auch eine Kombination aus mehreren Methoden möglich. Bei Bedarf können auch fehlende Werte berücksichtigt und "aufgefüllt" werden, z. B. wenn Dienstleistungen in bestimmten Regionen nicht verfügbar sind.
Korrektur, Kommentierung und Zusammenfassung der Einzelergebnisse auf unterschiedliche Weise - diese Schritte erhöhen die Transparenz für Kunden und Dienstleister. Die Verdichtung führt zu einer mehrdimensionalen Betrachtung der Ergebnisse aus verschiedenen Perspektiven und nach unterschiedlichen Bewertungskriterien. Wird die Verfügbarkeit von Diensten pro Kunde und Standort ermittelt, ist der standort- und kundenübergreifende Vergleich von Einzeldiensten für Servicemanager interessant, der service- und kundenübergreifende Vergleich von Standorten hingegen für Standortmanager.
Häufig werden die Ergebnisse der Verfügbarkeitsberechnung auch zur Umsetzung der im SLA definierten Bonus-Malus-Regeln und zur Berechnung der entsprechenden Pönalen verwendet. In einer laufenden Berichtsperiode liefert die Berechnung auch wichtige Inputs für das proaktive Management von Systemen und Services. So können auf Basis der vorliegenden Zwischenergebnisse Prognosen (Best Case, Worst Case) erstellt werden, auf deren Grundlage gegebenenfalls noch rechtzeitig Maßnahmen ergriffen werden können.
// Die IT-Verfügbarkeit ist entscheidend für den Erfolg: Ein System, das 365 Tage im Jahr rund um die Uhr arbeitet, soll eine Verfügbarkeit von 99,999% erreichen und darf nur 5,26 Minuten Ausfallzeit haben. Und das das ganze Jahr über!//
Hans Maurer, Mitbegründer von amasol und Experte für Technologie-Business-Management
Unsere Kompetenz
Profitieren Sie von über 25 Jahren fundierter Fachkompetenz und hochwertigen Dienstleistungen in unseren Kernbereichen.
Warum amasol
Wir wollen die Flexibilität steigern, den Mehrwert erhöhen, die Effizienz der IT verbessern und so den Geschäftserfolg steigern.
Unsere Partner
Entdecken Sie die Tools und Partnerschaften, die uns dabei unterstützen, Ihren Erfolg voranzutreiben und Ihre IT-Umgebung zu optimieren.
Unsere Veranstaltungen
Von Expertengesprächen bis hin zu praktischen Workshops verbinden wir Strategie und Technologie.Mehr entdecken

Schenker setzt bei User Experience Monitoring und Application Performance Management im Bereich Luft- und Seefracht auf Dynatrace und amasol
Die umfassende Unterstützung von Dynatrace für moderne Cloud-, On-Premise- und Hybrid-Umgebungen stellt zudem Skalierbarkeit und langfristige Anpassungsfähigkeit sicher. Das Ergebnis ist eine zuverlässigere, kosteneffizientere und einfacher zu verwaltende Observability-Lösung im Vergleich zu fragmentierten Systemen oder weniger integrierten Ansätzen.

Dynatrace & amasol: Stronger together
85 % der Technologieführer beobachten: die zahlreichen Tools, Plattformen, Dashboards und Applikationen machen Ihr Multicloud-Environment immer komplexer.
amasol vereinfacht den Betrieb von Multicloud-Environments, verbessert die Leistung und schafft - dank unserer ganzheitlichen Lösung - einen nahtlosen Geschäftsbetrieb.
Dynatrace & amasol: Stronger together
Dynatrace bietet wertvolle Einblicke in Ihre IT-Prozesse. amasol nutzt diese Informationen und verbindet sie mit Ihren Geschäftsprozessen.
Sie haben sich erfolgreich für unsere Exeon Workbench registriert.
Guten Tag,
vielen Dank für Ihre Anmeldung zur Workbench | Bedrohungserkennung mit KI-basierter Verhaltensanalyse.
Hier sind die wichtigsten Informationen:
Wann: Dienstag, 30. September 2025 | 10:00 - 11:00 Uhr
Wo: Online via Zoom
Wir freuen uns auf Ihre Teilnahme und auf interessante Diskussionen und Präsentationen rund um das Thema Detectability.
Mit freundlichen Grüßen
Laura Ilgner
Eine Woche vor der Veranstaltung erhalten Sie von uns eine Erinnerungsmail.
Erfolgreiche Anmeldung bei der DX NetOps Usergroup in Wien
Guten Tag,
vielen Dank für Ihre Anmeldung zu der DX NetOps Usergroup von amasol.
Hier sind die wichtigsten Informationen:
Wann: Donnerstag, 09. Oktober 2025 | 9:45 - 17:00 Uhr
Wo: im MEZZANIN Meetings & Events by Zeitgeist Vienna nahe Wiener Hauptbahnhof
Hier finden Sie Informationen zur Lage und Anfahrt.
Wir freuen uns auf Ihre Teilnahme und auf interessante Diskussionen und Präsentationen rund um das Thema Broadcom.
Mit freundlichen Grüßen
Laura Ilgner
Eine Woche vor der Veranstaltung erhalten Sie von uns eine Erinnerungsmail.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.