
Beispiel 2: Erweiterung der Icinga-Anbindung an CA SOI für dynamische Alarmtitel
Ursprünglich konnten Alarmmeldungen von Icinga an CA SOI nur eine feste Zeichenfolge als Alarmtitel oder Alarmzusammenfassung enthalten, die dann als Vorfallstitel verwendet wird. Dieser Titel war fest - unabhängig von der Priorität des Alarms - und erwies sich daher manchmal als nicht aussagekräftig genug.

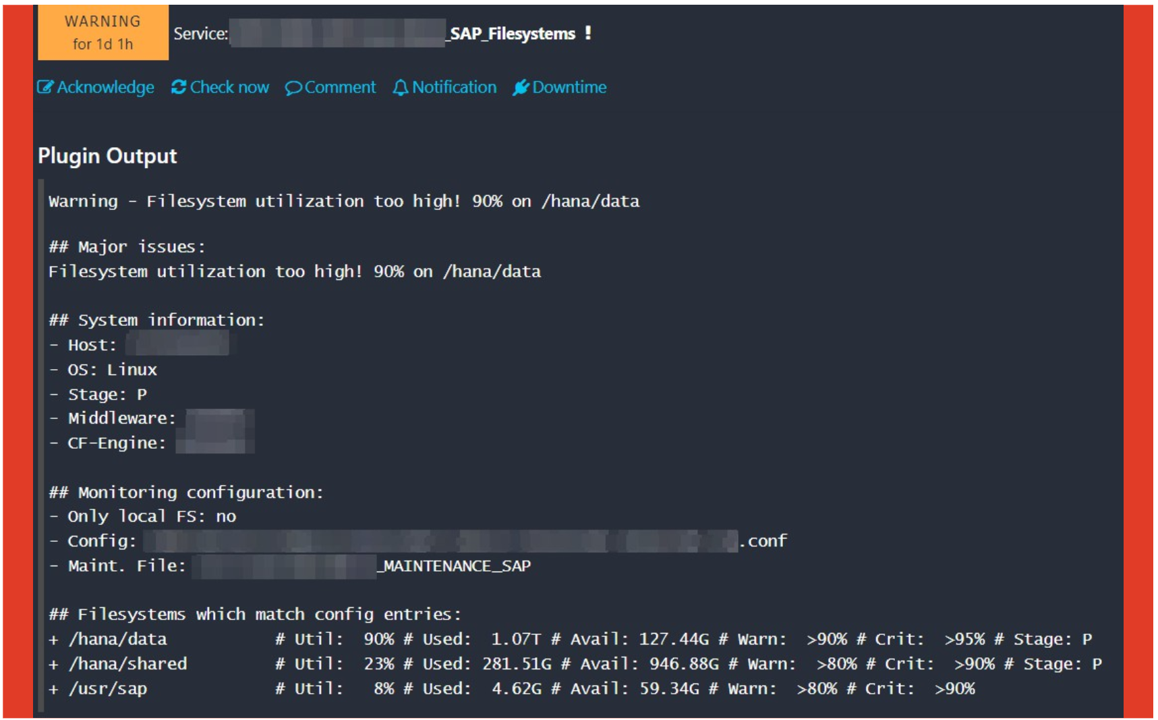
amasol hat das Optimierungspotenzial erkannt, wenn die aktuellen Messwerte auch über die Ausgabe der Icinga-Plugins in den Alarmtitel übertragen werden. Dies ist jedoch nicht für jeden Icinga-Dienst möglich, da die Ausgabe einiger Plugins nicht den Anforderungen eines Alarmtitels entspricht. Die von amasol entwickelten Plugins sind jedoch alle darauf ausgelegt, eine detaillierte und nützliche Ausgabe zu liefern, die sich als Alarm- und Ereignistitel eignet.
amasol entwickelte daraufhin einen Schalter im Icinga-Service (und damit für jeden Service individuell konfigurierbar) zur Umschaltung der Titelanzeige. Nach wie vor wird ein fester und vordefinierter Alarmtitel an CA SOI oder die erste Zeile der Plugin-Ausgabe gesendet.
Ein erweitertes Benachrichtigungsskript verwendet die erste Zeile der Plugin-Ausgabe, wenn der Schalter aktiviert ist, und entfernt die Statusinformationen ("Warnung: ", "WARNUNG - ", "Kritisch: ", ...). Die bereinigte "Ereignismeldung" wird dann an die Alarmkonsole als Alarmtitel gesendet.
Bei allen von amasol entwickelten Plugins ist es möglich, diese Option zu aktivieren und so - wenn vom Kunden gewünscht - immer hilfreiche und präzise Alarmtitel zu übermitteln.

Beispiel 3: Erweiterung der Verbindung von Icinga zu CA SOI für variable CIs
Ursprünglich wurden Alarmmeldungen mit festen, im Icinga-Dienst konfigurierten CIs an SOI gesendet. Dieses Konstrukt ist jedoch für verschiedene Anwendungen zu starr. Zum Beispiel hat bei der grundlegenden Überwachung von Webservern jeder Webserver auf jedem Server sein eigenes CI. Es müsste also für jeden Webserver auf jedem Server ein eigener Icinga-Service eingerichtet werden. Ein weiteres Beispiel ist die SAP-Überwachung: Jede SAP-Komponente hat ihr eigenes CI, aber aufgrund der Komplexität der SAP-Umgebung wäre es nicht möglich, jede SAP-Komponente auf einem Server einzeln über einen entsprechenden Dienst zu überwachen - und zwar für jeden SAP-Server.
Die erforderliche Flexibilität wird dadurch erreicht, dass das CI durch das Monitoring-Plugin auf dem Server ermittelt und als CI in der Benachrichtigung gesendet wird.
Für solche Spezialfälle entwickelt amasol Icinga-Plugins, die das CI auf dem jeweiligen Host ermitteln und in der Plugin-Ausgabe in einem vordefinierten Format ausgeben.
Darüber hinaus wurden das Benachrichtigungsskript und der Icinga-Service um einen weiteren Schalter erweitert, um zusätzlich das CI aus der Plugin-Ausgabe zu lesen und anstelle des im Service definierten CIs an CA SOI zu senden.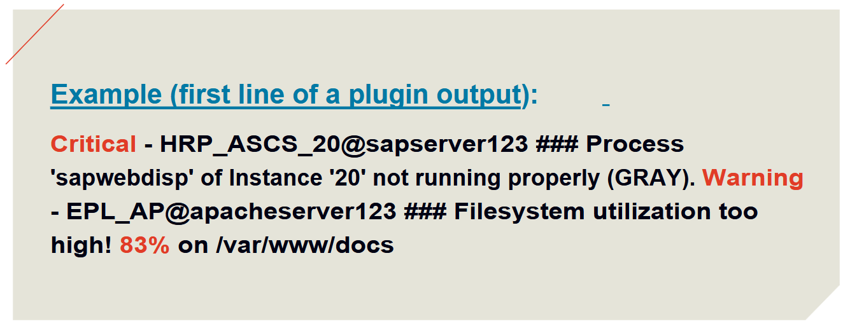
Benutzerdefinierte Plugins (basierend auf einem eigenen Framework für bash-basierte Plugins)
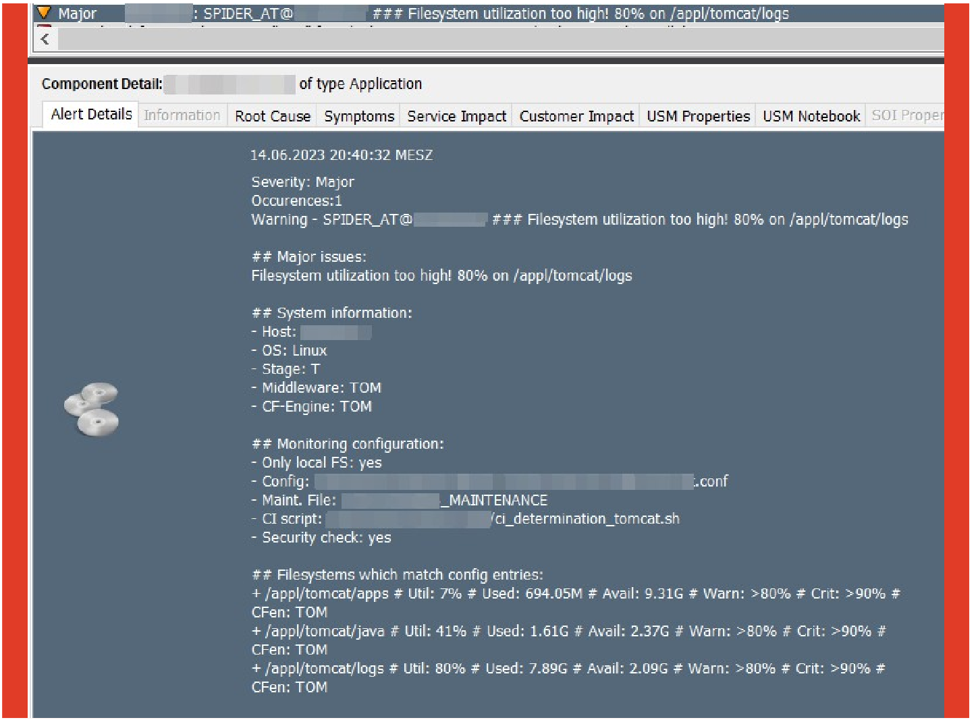
Wie eingangs erwähnt, hat amasol eine ganze Reihe von eigenen Plugins für Icinga entwickelt, die auf Linux, AIX, HP-UX und SunOS laufen. Die Plugin-Ausgabe all dieser Plugins wurde mit System-/Metainformationen angereichert.
Alle Plugins können über Flag-Dateien in den "Wartungsmodus" versetzt werden (weiterhin aktive Überwachung, aber deaktivierte Alarmierung/Benachrichtigung). Zusätzlich können Alarmmeldungen über einen Schalter für niedrige Stufen (z.B. Stufe "Test") deaktiviert werden. Dies ist unabhängig davon möglich, wo der Dienst läuft: Das Plugin kümmert sich darum.
Die Plugins sind "cluster-aware", d.h. es erfolgt keine Alarmierung bei inaktiven Clusterknoten.
Zusätzlich werden aufgerufene Programme (z.B. df) überwacht und hängende Prozesse (mit Ausnahme von Prozessen, die über sudo gestartet wurden) nach Erreichen eines konfigurierbaren Timeouts "getötet". Dies stellt sicher, dass der Timeout der Icinga-Dienste keine Prozesse (Waisen) auf dem System zurücklässt und dem System nach einer bestimmten Zeit seine Ressourcen entzieht. Es werden Informationen über hängende Prozesse bereitgestellt, die über sudo gestartet wurden.
Unsere Kompetenz
Profitieren Sie von über 25 Jahren fundierter Fachkompetenz und hochwertigen Dienstleistungen in unseren Kernbereichen.
Warum amasol
Wir wollen die Flexibilität steigern, den Mehrwert erhöhen, die Effizienz der IT verbessern und so den Geschäftserfolg steigern.
Unsere Partner
Entdecken Sie die Tools und Partnerschaften, die uns dabei unterstützen, Ihren Erfolg voranzutreiben und Ihre IT-Umgebung zu optimieren.
Unsere Veranstaltungen
Von Expertengesprächen bis hin zu praktischen Workshops verbinden wir Strategie und Technologie.
