
Full-Stack-Observability mit bewährter KI
Bündeln Sie Metriken, Logs, Traces und den Betrieb in einer vernetzten Plattform mit Grafana Cloud.
Sehen Sie, wie Teams volle Sichtbarkeit über Applikationen, Infrastruktur und die User Experience erhalten, ohne zwischen Tools wechseln zu müssen. Mit amasol als Partner*in wird Grafana zu einer strukturierten, skalierbaren Observability-Basis, die genau darauf zugeschnitten ist, wie Ihre Systeme tatsächlich laufen.
Grafana Cloud: Eine Ansicht. Unendliche Klarheit.
Grafana Cloud vereint Logs, Metriken und Traces in einer einzigen offenen Plattform, die Ihren Teams volle Sichtbarkeit über Systeme, Services und Umgebungen hinweg bietet. Basierend auf dem modular aufgebauten Observability-Stack von Grafana – Grafana Loki (Logs), Grafana Tempo (Traces), Grafana Mimir (Metriken) und Grafana (Visualisierung) – ermöglicht sie es Entwickler*innen, SREs und Platform-Teams, Probleme schneller zu erkennen, Daten mühelos zu korrelieren und sicher zu agieren, ohne in einen Vendor Lock-in zu geraten.
Mit amasol als Partner*in schöpfen Sie das volle Potenzial dieses Stacks aus. Wir konzipieren und betreiben Ihre Telemetrie-Pipeline und stellen sicher, dass Ihre Daten vom ersten Tag an strukturiert, skalierbar und verwertbar sind. Wir unterstützen Teams bei der Implementierung von Best Practices für Data Governance, Access Control und System Reliability, damit Grafana nicht zu einem weiteren operativen Risiko wird. Von der initialen Architektur bis zum laufenden Betrieb stellt amasol sicher, dass Ihr Setup konsistent läuft, mit Ihrer Umgebung skaliert und verwertbare Insights ohne unnötige Komplexität liefert.
Ihre Vorteile
Full-stack observability
Korrelieren Sie Metriken, Logs und Traces in einem einzigen vereinheitlichten Workflow
Open source
Nutzen Sie Community-getriebene Innovationen und offene Standards ohne Lock-in
Daten-Demokratisierung
Vereinheitlichen Sie unterschiedliche Datenquellen in einer Single Pane of Glass, ohne eine Migration durchführen zu müssen
Full-Stack Observability
Verstehen Sie Ihre Systeme End-to-End durch Logs, Metriken und Traces in einer vereinheitlichten Ansicht. Weiterlesen
AI ASSISTANT
Nutzen Sie natürliche Sprache, um Daten abzufragen, Dashboards zu erstellen und Untersuchungen über Ihren gesamten Observability-Stack hinweg zu beschleunigen. Weiterlesen
Dashboards & Datenvisualisierung
Verwandeln Sie komplexe Telemetrie in klare und verwertbare Dashboards für jedes Team. Weiterlesen
Incident Response & Management
Koordinieren Sie Alerts, On-Call und Response-Workflows an einem zentralen Ort. Weiterlesen
Synthetic Monitoring
Testen Sie User Journeys und die Systemverfügbarkeit kontinuierlich von Standorten auf der ganzen Welt. Weiterlesen
Performance & Load Testing
Validieren Sie das Systemverhalten unter realem Traffic und Spitzenlastbedingungen vor dem Release. Weiterlesen
Grafana in seiner Kernfunktion
Warum Grafana Cloud für Full-Stack-Observability nutzen?
Klar sehen. Schneller handeln.
Verstehen Sie den Systemzustand in Echtzeit, indem Sie Services, Infrastruktur und Datenbanken in einer vereinheitlichten Ansicht verbinden. Teams können Abhängigkeiten frühzeitig erkennen, Probleme schneller identifizieren und Incidents lösen, bevor diese Auswirkungen auf die Nutzer*innen haben.
Untersuchen Sie smarter
Gehen Sie vom reaktiven Troubleshooting zur geführten Untersuchung über, mit einer KI, die Muster hervorhebt, Anomalien erklärt und dabei hilft, die Root Cause schneller aufzudecken. Nutzen Sie Live-Dashboards, um Änderungen zu validieren und die Response-Qualität kontinuierlich zu verbessern.
Sichtbarkeit skalieren, Kosten kontrollieren
Fokussieren Sie sich mit Adaptive Telemetry auf die Signale, die zählen, um Rauschen zu reduzieren und kritische Daten in Ihrer Observability-Pipeline zu priorisieren. Optimieren Sie die Kosteneffizienz über Metriken, Logs und Traces hinweg, während Sie von kleinen Teams bis hin zu Enterprise-Umgebungen skalieren.
Full-stack observability | von fragmentierten Signalen zu vernetzten Insights
Full-Stack-Observability ist die Fähigkeit, den vollständigen Zustand Ihrer Systeme zu verstehen, indem Metriken, Logs und Traces über Applikationen, Infrastruktur und User-Interaktionen hinweg korreliert werden. Grafana Cloud liefert dies durch einen offenen, auf Standards basierenden Ansatz rund um OpenTelemetry, der es Organisationen ermöglicht, Telemetrie zu vereinheitlichen, ohne in einen Vendor Lock-in oder die Abhängigkeit von proprietären Systemen zu geraten. Dieser offene und modular aufgebaute Ansatz erlaubt es Teams, Daten in jeder Umgebung zu sammeln, zu speichern und zu visualisieren, während sie gleichzeitig die Kontrolle über ihre Architektur behalten. Da Systeme immer verteilter und komplexer werden, bietet dies eine skalierbare Basis für Observability, ohne Datensilos zu schaffen oder die zukünftige Flexibilität einzuschränken.
Kubernetes Monitoring with Grafana Cloud | Sofortige Sichtbarkeit, KI-gestützte Insights und geführte Fixes über Ihre Cluster hinweg
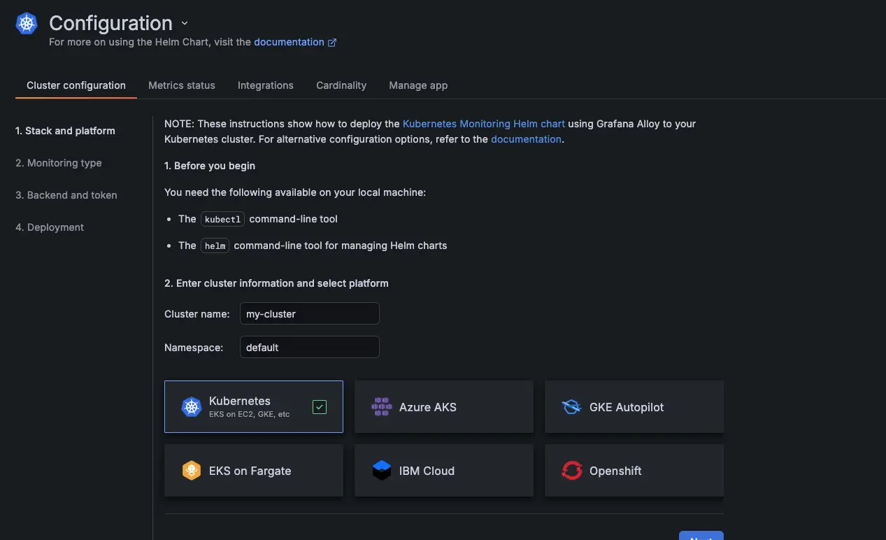
Grafana Cloud bringt Metriken, Logs und Traces aus Kubernetes-Umgebungen in einer einzigen Ansicht zusammen und hilft Teams dabei, den Systemzustand über Cluster, Services und Workloads hinweg zu verstehen. Es reduziert die Komplexität in dynamischen, containerisierten Umgebungen und unterstützt Teams dabei, Probleme schneller zu erkennen und zu lösen, während Performance und Kosten unter Kontrolle bleiben. Bei amasol konzipieren und implementieren wir Kubernetes-Observability-Setups, die skalierbar funktionieren und sicherstellen, dass Ihre Telemetrie strukturiert, zuverlässig und auf den tatsächlichen Betrieb Ihrer Cluster abgestimmt ist.
Sofortige Insights, schnellere Time to Value
Stellen Sie Grafana Cloud mittels Helm-basierter Installation und Out-of-the-box-Alerting bereit, um sofortige Sichtbarkeit des Kubernetes-Zustands zu erhalten. Integrierte Dashboards machen wichtige Signale wie CPU-Throttling, Memory Pressure, Workload-Sättigung und Alert-Bedingungen auf Cluster-Ebene sichtbar. Korrelierte Metriken und Logs reduzieren den Zeitaufwand für den Wechsel zwischen Signalen während der Incident-Erkennung.
KI-gestützte Kubernetes-Analyse
KI-gestützte Untersuchungen helfen dabei, Alerts mit dem zugrunde liegenden Cluster-Verhalten zu korrelieren, wobei wahrscheinliche Auswirkungen hervorgehoben und nächste Schritte während Incidents angeleitet werden. Dies reduziert die manuelle Log-Korrelation und beschleunigt das Verständnis von Service-Degradation über verteilte Workloads hinweg.
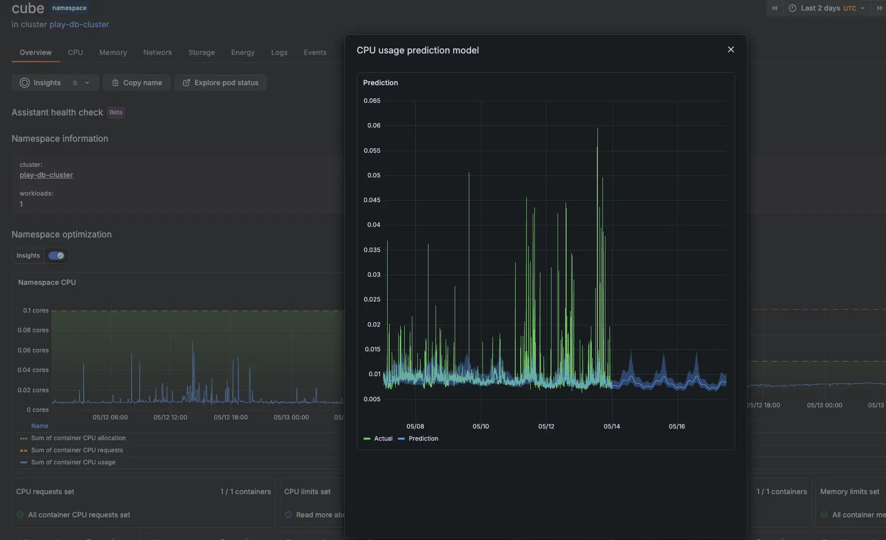
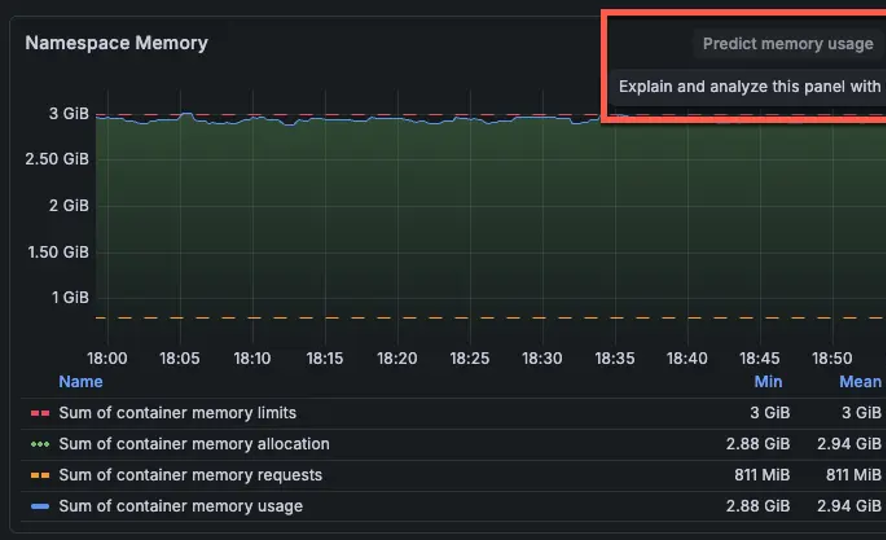
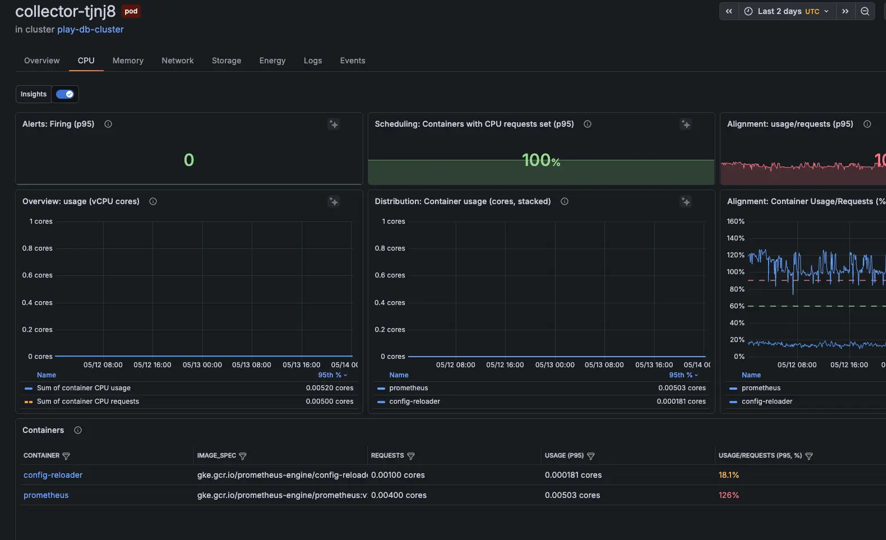
Ressourcennutzung optimieren, analysieren und antizipieren
Analysieren Sie CPU-, Memory- und Netzwerkauslastung im Vergleich zu Requests und Limits, um Ineffizienzen und Over-Provisioning zu identifizieren. Die Time-Series-Analyse des Workload-Verhaltens ermöglicht eine bessere Kapazitätsplanung und Kostenkontrolle über Multi-Cluster-Umgebungen hinweg, einschließlich Bursty- und Autoscaling-Workloads.
360-Grad-Sichtbarkeit, von Clustern bis zu Containern
Navigieren Sie vom Cluster-Zustand bis hinunter zu Nodes, Pods und einzelnen Workloads unter vollständiger Beibehaltung des Kontextes. Vergleichen Sie historische Daten mit der Performance in Echtzeit, um Anomalien zu identifizieren, Auswirkungen von Deployments zu verfolgen und Probleme über Kubernetes-Primitiven hinweg zu debuggen, einschließlich CronJobs und ephemeral Workloads.
Application observability with Grafana Cloud | End-to-End-Sichtbarkeit, schnellere Root-Cause-Analyse und vereinheitlichte Service-Insights
Grafana Cloud vereint Metriken, Logs, Traces und Profile, damit Teams den Status ihrer Anwendungen an einem zentralen Ort einsehen können. Dies trägt dazu bei, den Zeitaufwand für die Erkennung, Untersuchung und Behebung von Vorfällen in verteilten Systemen zu reduzieren. Basierend auf offenen Standards wie Prometheus bleibt die Lösung flexibel und vermeidet einen Vendor Lock-in bei der Skalierung von Anwendungen. Unsere Berater*innen entwerfen und betreiben Observability-Setups, die das Anwendungsverhalten besser interpretierbar machen, Noise reduzieren und sicherstellen, dass sich die Teams auf die entscheidenden Signale konzentrieren können.
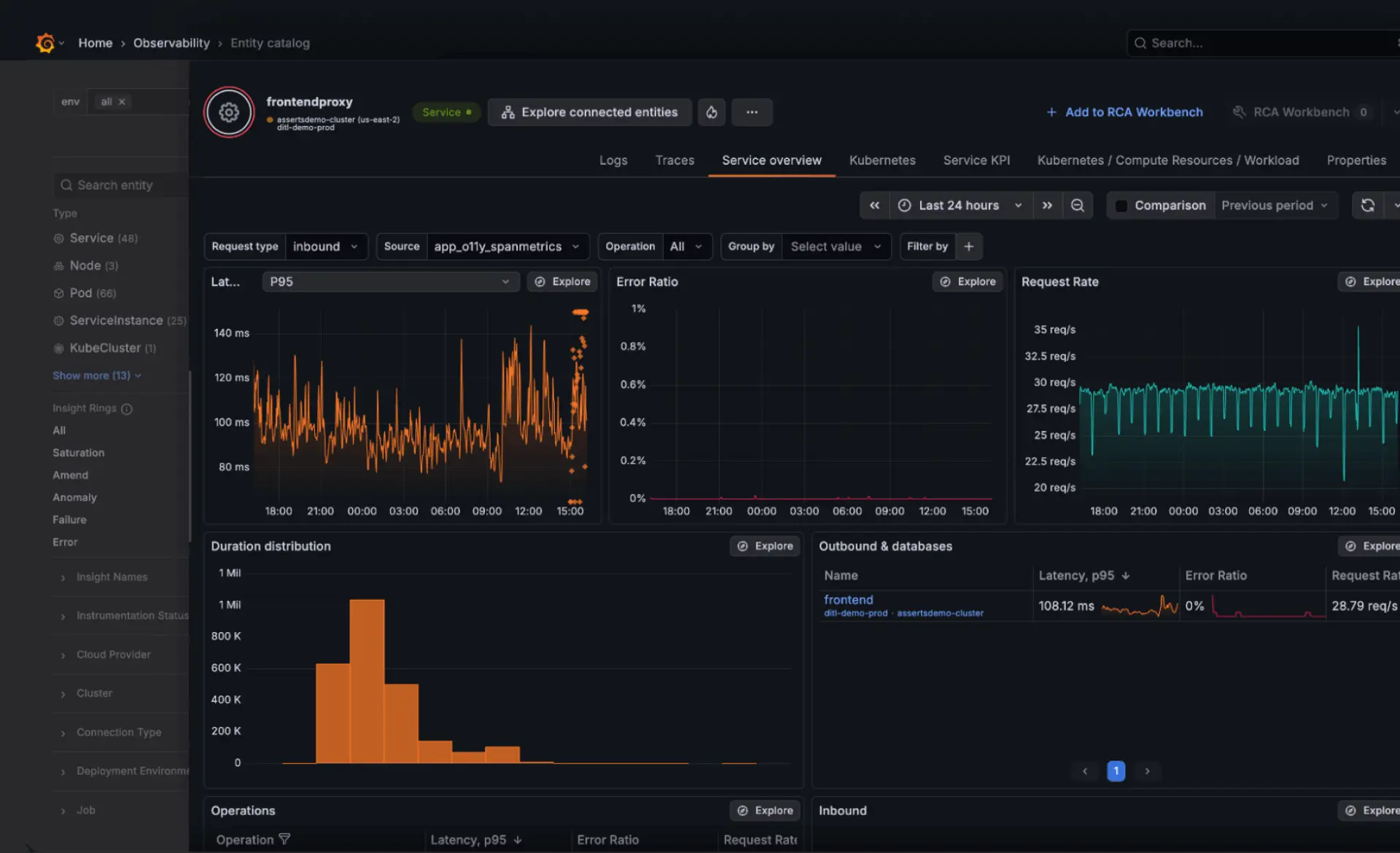
End-to-end observability
Sehen Sie Services in Echtzeit über ein Service-Inventar ein, das Zustand, Performance und Abhängigkeiten in Ihrem gesamten System anzeigt. Service-Maps und RED-Metriken helfen Teams dabei, fehlerhafte Services und deren Upstream-Auswirkungen schnell zu identifizieren. Automatisches Baselining hebt Abweichungen in der Performance hervor, sodass Probleme in komplexen Umgebungen frühzeitig erkannt werden.
Signale über den gesamten Stack hinweg korrelieren
Grafana Cloud führt Metriken, Logs, Traces und Profile unter Nutzung des OpenTelemetry-Datenmodells zusammen. Es verbindet Anwendungs- und Infrastrukturdaten, sodass Teams in einem einzigen Workflow von Metriken zu Logs und Traces wechseln können, um Untersuchungen zu beschleunigen.
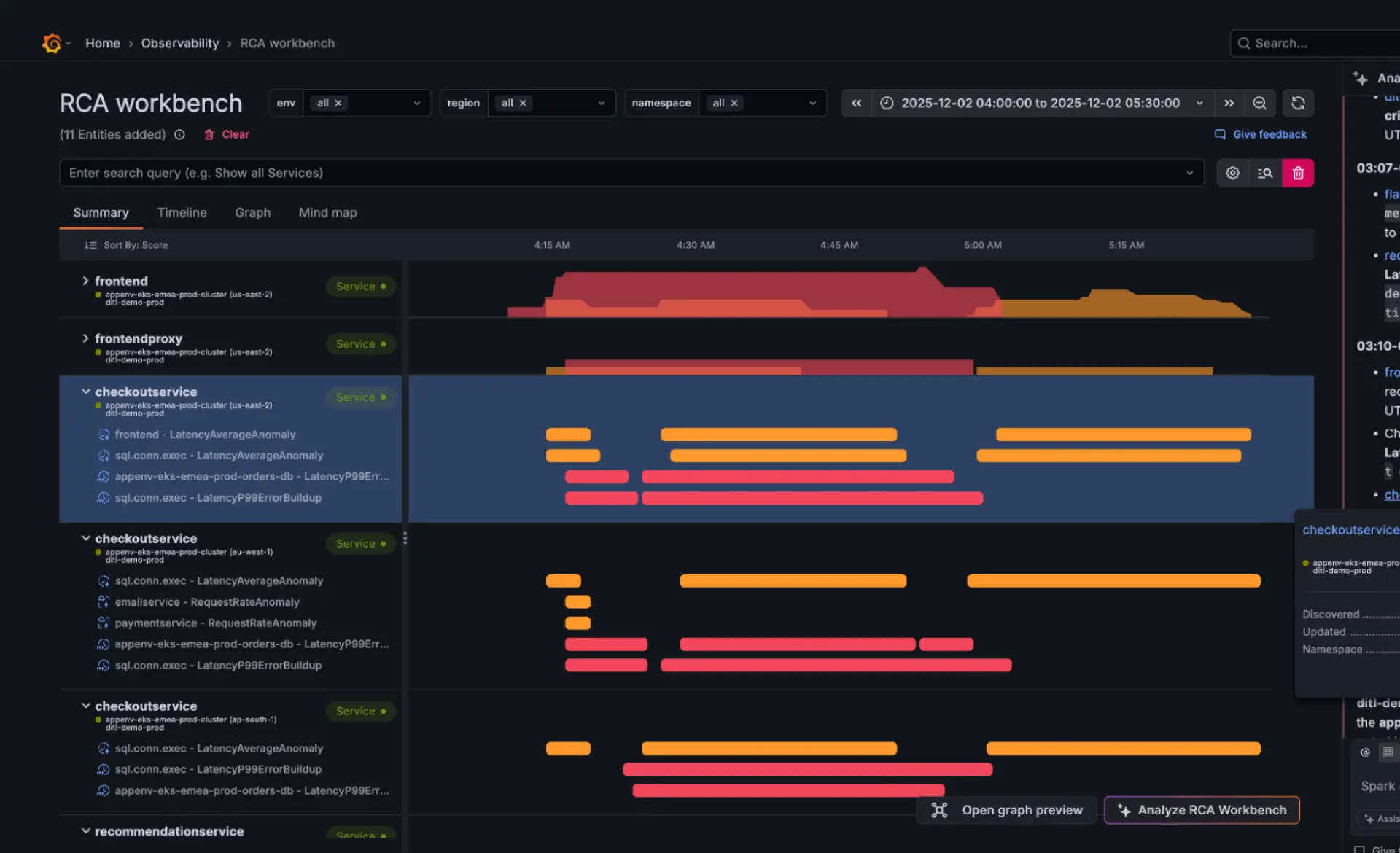
Finden Sie Root-Causes schneller mit dem Knowledge Graph
Der Knowledge Graph verbindet Signale über Services, Abhängigkeiten und Zeitlinien hinweg, um wahrscheinliche Ursachen von Incidents aufzuzeigen. Durch die Verknüpfung von Fehlern, Sättigung und Performance-Änderungen in einem Kontext hilft er Teams dabei, die Zeit bis zur Fehlerbehebung zu verkürzen und zu verstehen, wie sich Probleme im System ausbreiten.
Kompatibel mit OpenTelemetry und Prometheus
Grafana Cloud lässt sich nativ in OpenTelemetry und Prometheus integrieren, sodass Teams die Instrumentierung nur einmal vornehmen müssen und Vendor Lock-in vermeiden. Mit Tools wie Grafana Alloy können Telemetrie-Pipelines Daten über Metriken und Traces hinweg konsistent erfassen und routen.
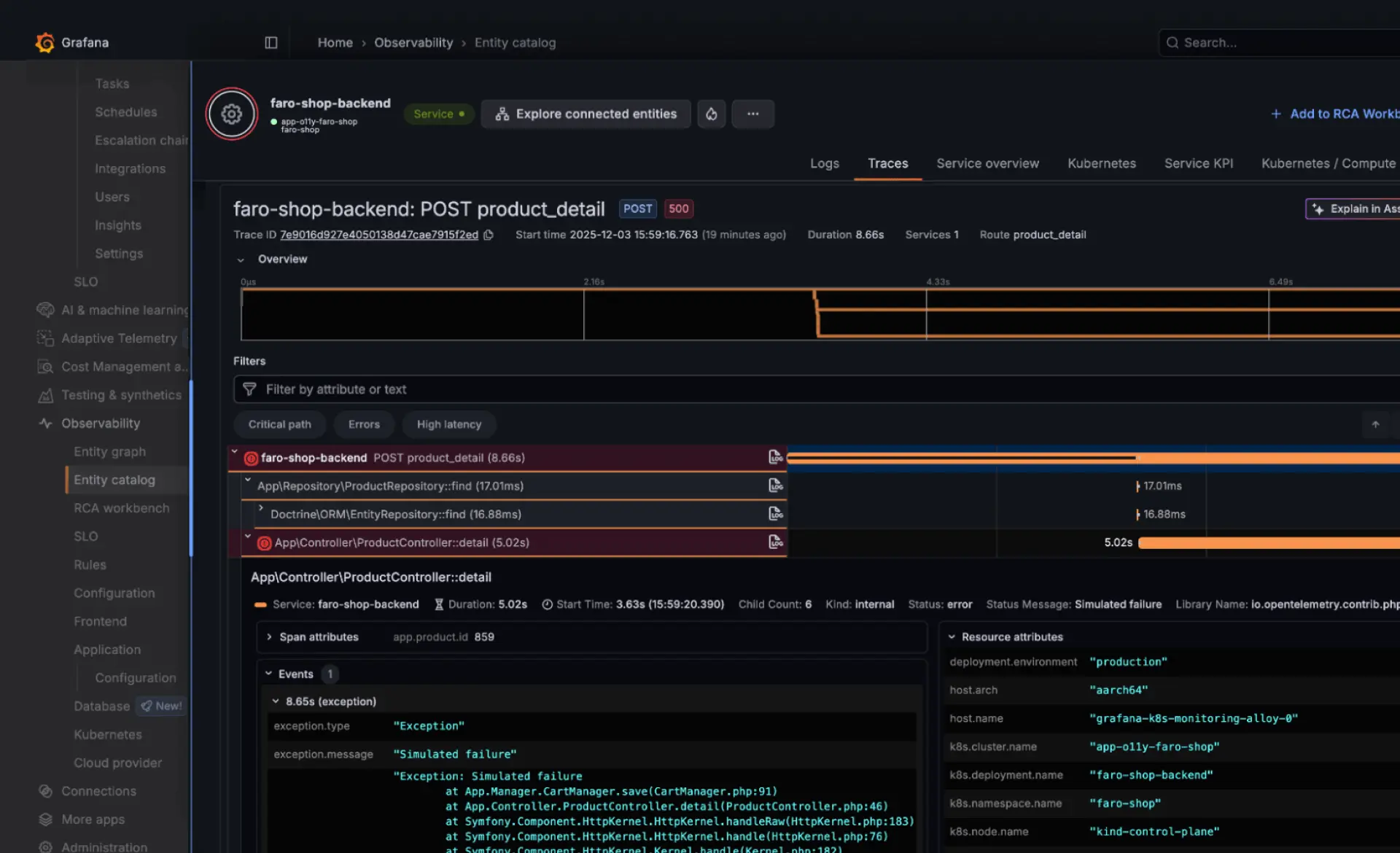
Frontend observability with real user monitoring (RUM) | Erkennen Sie Probleme bevor Kund*innen sie melden
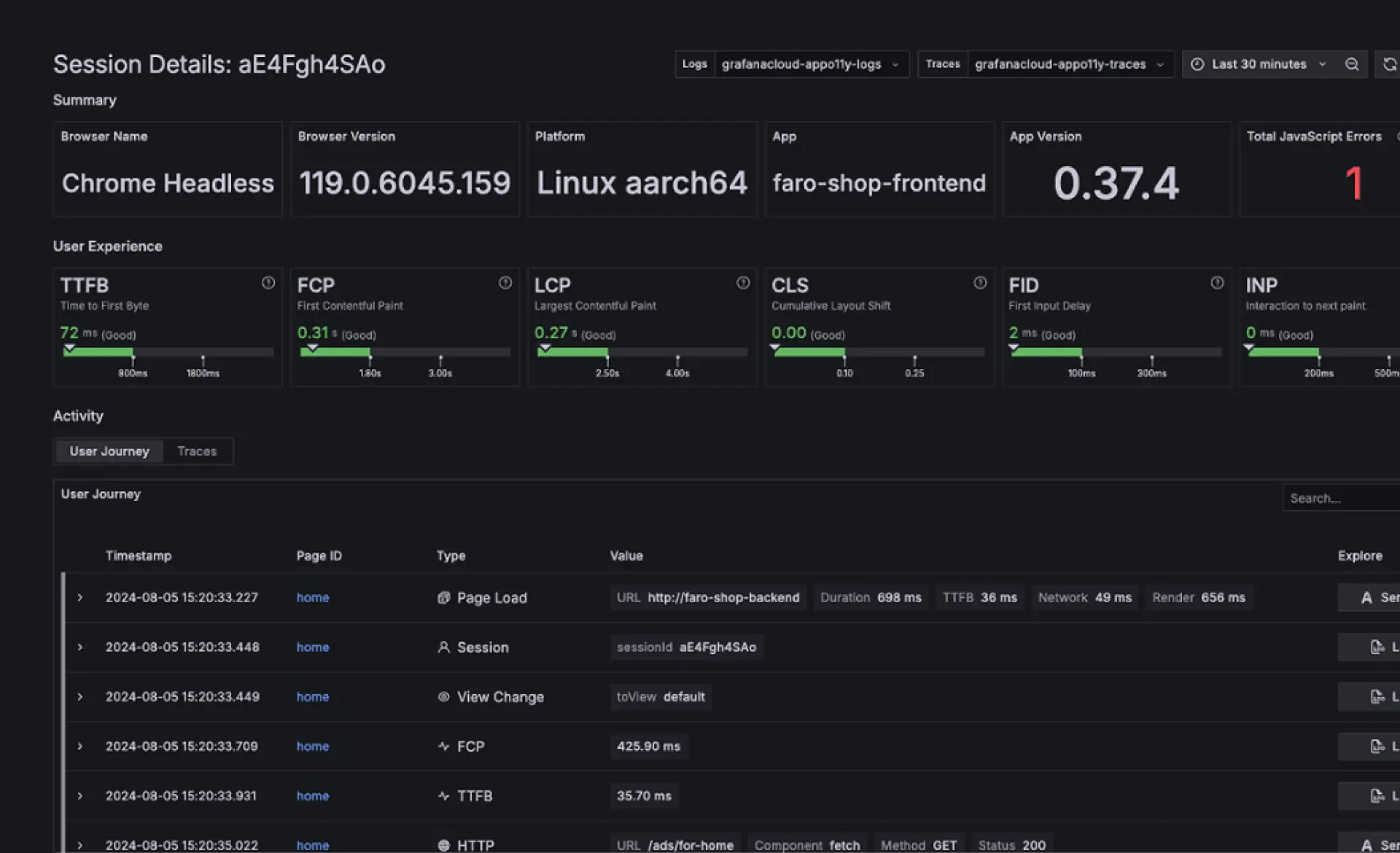
Grafana Cloud verknüpft das Frontend-Verhalten mit der Backend-Performance, damit Teams verstehen können, wie sich Systemänderungen auf Nutzerinteraktionen auswirken. Dies hilft dabei, Regressionen frühzeitig zu erkennen, die Auswirkungen von Releases zu messen und Probleme zu beheben, bevor sie Endnutzer*innen beeinträchtigen. amasol unterstützt Sie dabei, Real User Monitoring korrekt zu implementieren, indem wir sicherstellen, dass Ihre Daten sauber, konsistent und für aussagekräftige Analysen strukturiert sind. So können sich Ihre Teams auf die Verbesserung von Performance und User Experience konzentrieren, anstatt sich mit der Komplexität der Instrumentierung zu befassen.
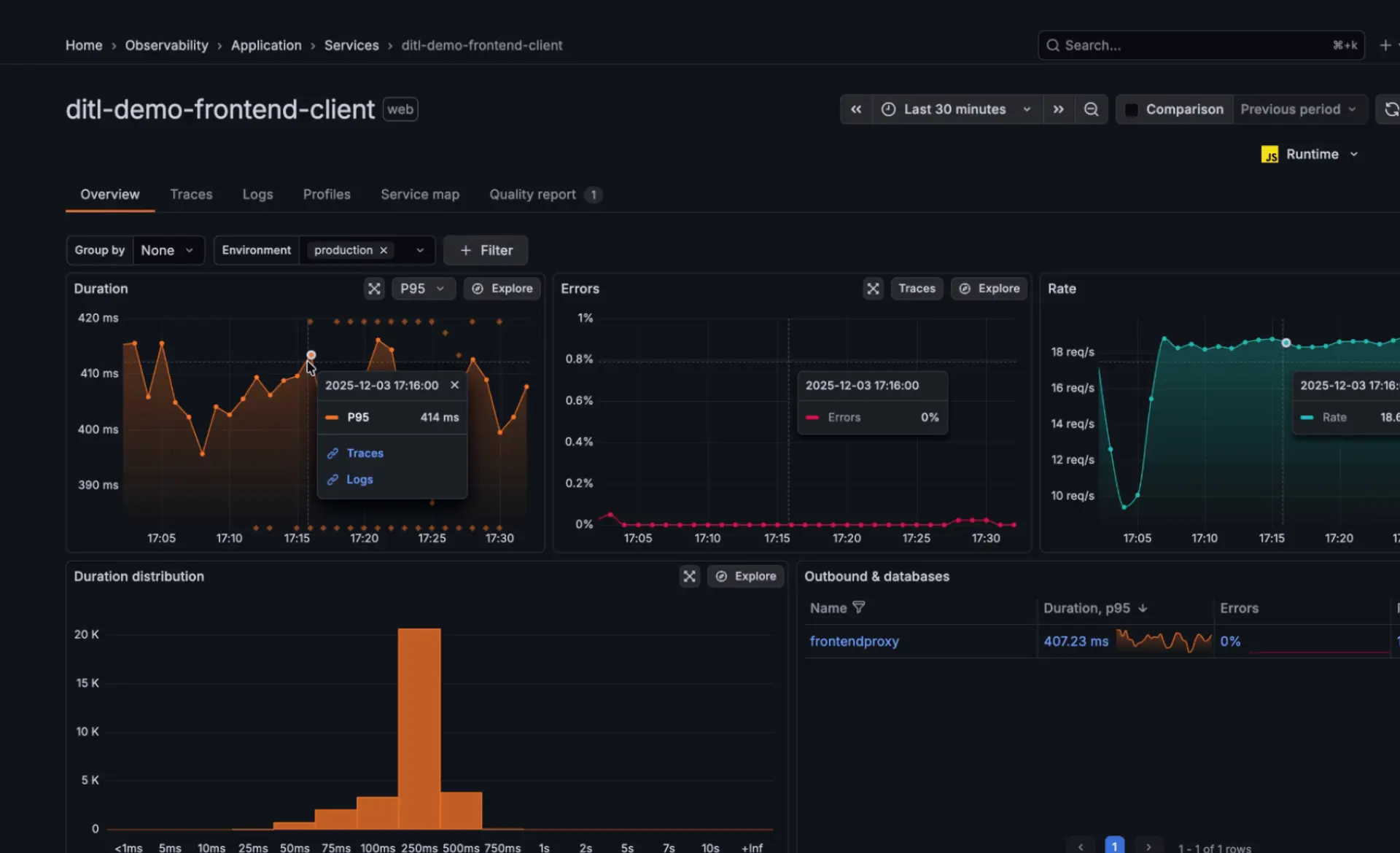
Überwachen Sie die End-User*innen-Experience
Grafana Cloud RUM hilft Ihnen dabei, die tatsächliche Performance der Userinnen zu messen, einschließlich Seitenladezeiten, Interaktionen und Layout-Shifts. Sie können die Performance nach Gerät, Version oder Session aufschlüsseln, um zu verstehen, wie verschiedene Userinnen Ihre Anwendung erleben.
Verfolgen Sie Fehler mit vollständigen Stack-Traces
Priorisieren Sie Frontend-Probleme nach Schweregrad, Häufigkeit und Auswirkungen. Umfangreiche Fehlerdaten und Stack-Traces helfen Ihnen dabei, genau zu identifizieren, an welcher Stelle im Code Probleme auftreten, und reduzieren den Zeitaufwand für das Erraten von Root-Causes.
End-to-End-Sichtbarkeit in jede User-Interaktion
Rekonstruieren Sie User-Journeys über Session-Timelines, die Frontend-Events mit Backend-Traces kombinieren. Dies erleichtert das Verständnis von Performance-Bottlenecks über Netzwerk-, Rendering- und Service-Layer hinweg.
Erstellen Sie benutzerdefinierte Grafana Cloud Dashboards
Erstellen Sie benutzerdefinierte Grafana Cloud Dashboards, die auf verschiedene Stakeholder*innen zugeschnitten sind und Frontend-Performance-Daten aus Logs und Traces nutzen. Dies ermöglicht es Teams, sich auf die für sie relevanten Metriken zu konzentrieren, ohne den gesamten Systemkontext zu verlieren.
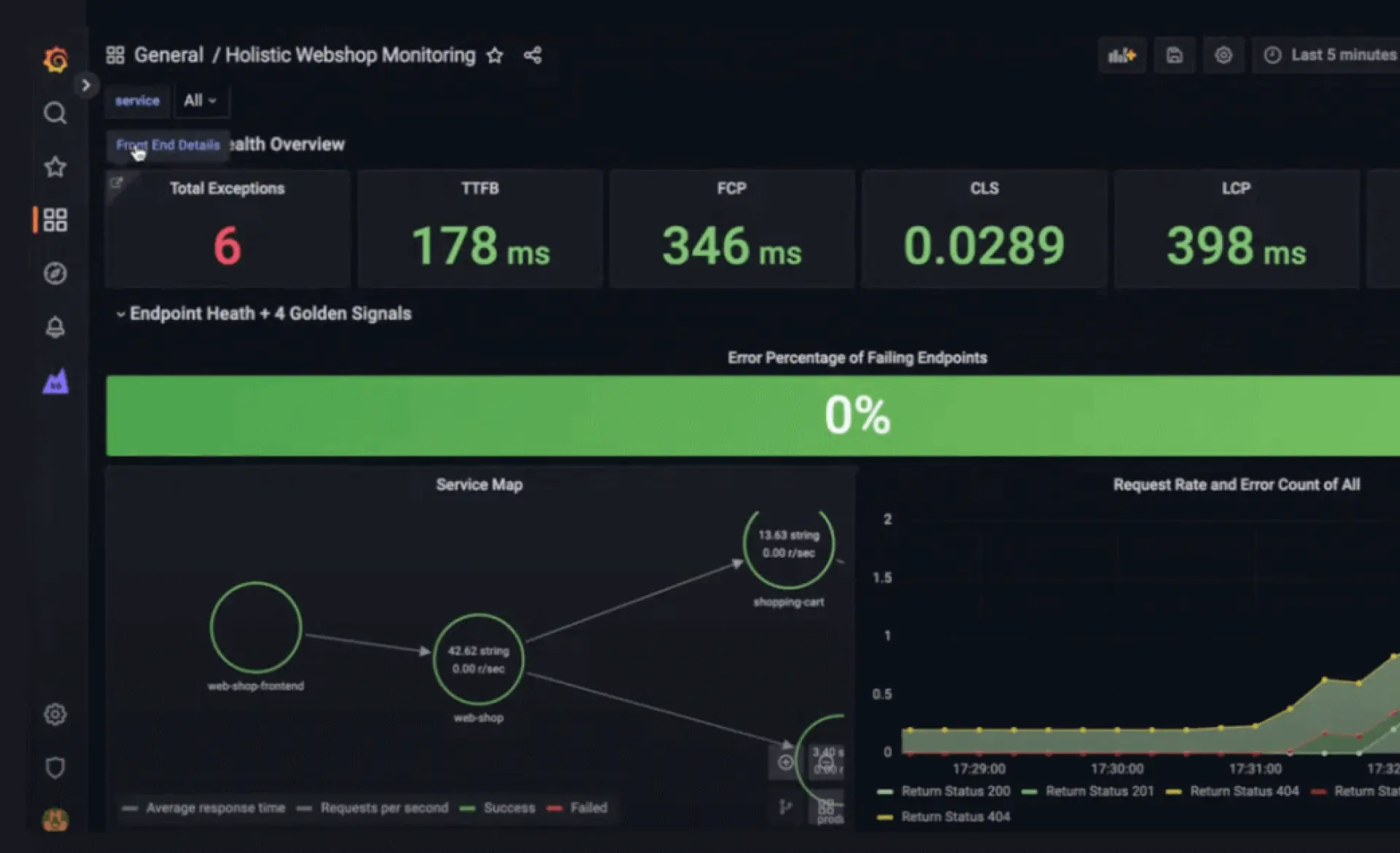
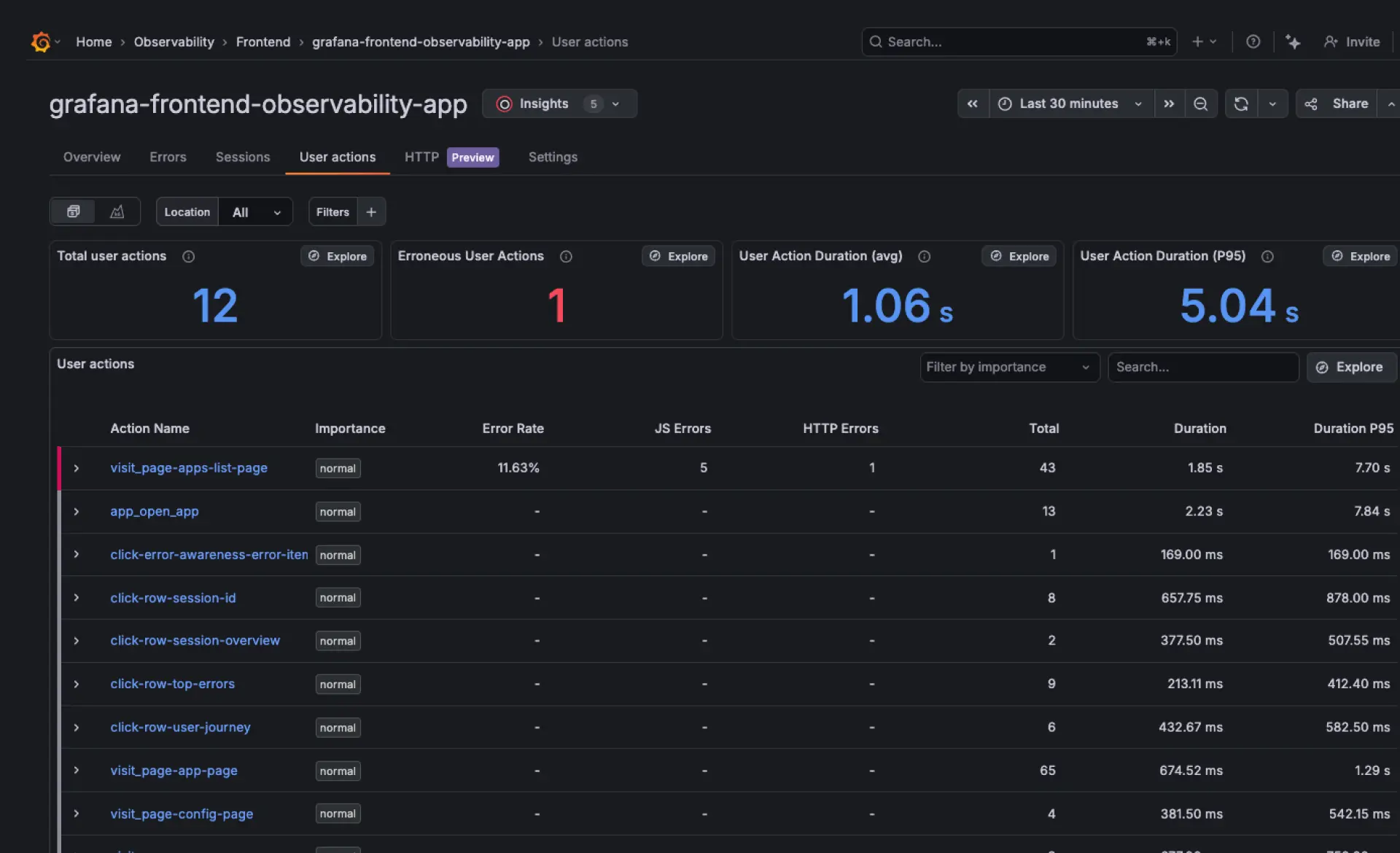
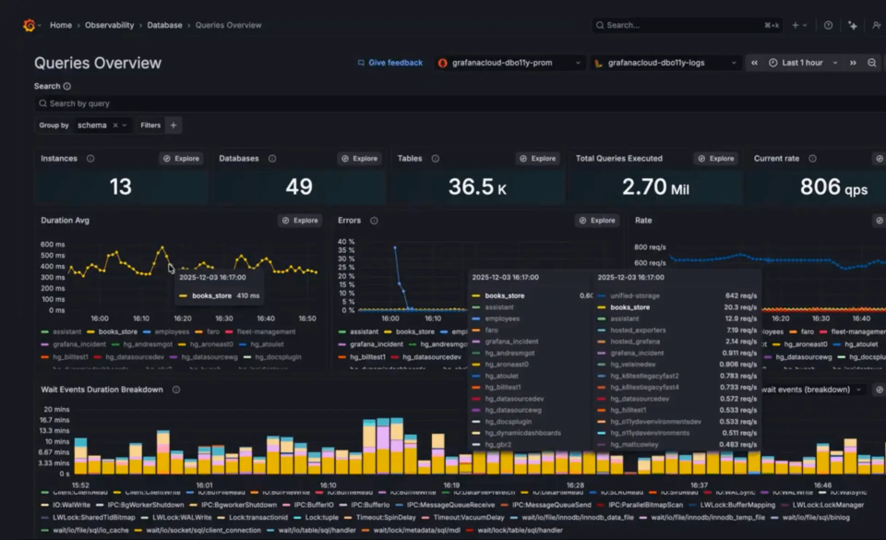
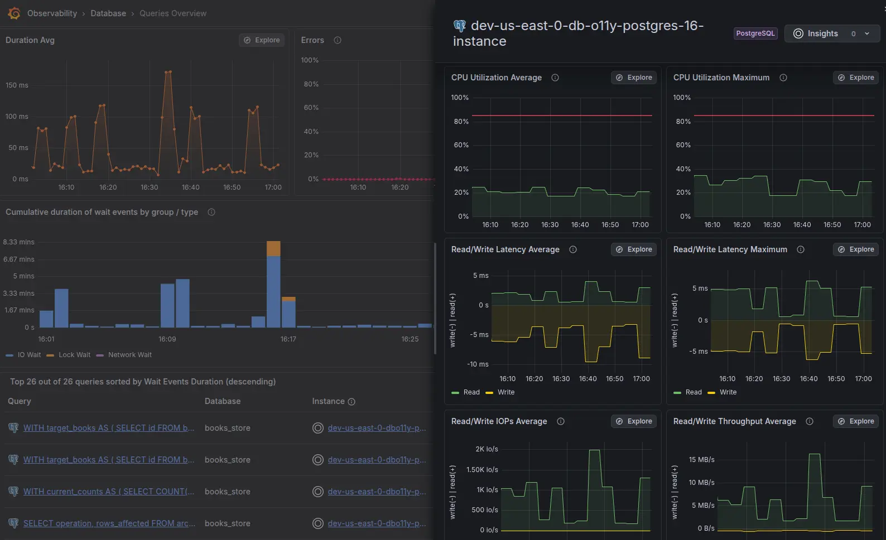
Database observability | Schnellerer Einblick in die Query-Performance und Datenbank-Bottlenecks.
Grafana Cloud hilft Teams dabei, langsame Queries mit Systemsignalen wie CPU-, Memory- und I/O-Auslastung zu verknüpfen, um zu verstehen, wie die Datenbank-Performance unter Last beeinflusst wird. Engineers können von der Erkennung von Verlangsamungen direkt zur Identifizierung der exakten Queries und der dahinterliegenden Ausführungspfade übergehen, was die Root-Cause-Analyse schneller und präziser macht. Für MySQL- und PostgreSQL-Umgebungen werden zudem ineffiziente Queries und fehlende Indizes hervorgehoben, um die Performance nachhaltig zu verbessern. Bei amasol unterstützen wir Teams bei der Operationalisierung von Database Observability, indem wir die Telemetrie klar strukturieren und es Engineers ermöglichen, sich auf die Behebung von Performance-Problemen zu konzentrieren, anstatt komplexe Observability-Daten zu verwalten.
Kontextualisieren Sie den Datenbank-Status
Grafana Cloud verbindet die Datenbank-Performance mit Upstream-Services über den Entity Catalog und den Knowledge Graph. Dies hilft Teams zu verstehen, wie sich langsame Queries und Resource Contention auf das gesamte Systemverhalten auswirken. Datenbank-Metriken können zudem mit Infrastruktur-Signalen kombiniert werden, um Sättigung und Performance-Bottlenecks über Services hinweg zu identifizieren.
Deep-Dive-Diagnose
Filtern und analysieren Sie Queries nach Latenz, Fehlern oder Ausführungszeit, um Performance-Probleme zu isolieren. Visuelle Explain-Plans helfen dabei, ineffiziente Operationen wie Full-Table-Scans aufzudecken, während normalisierte Query-Patterns die Erkennung von Regressionen im Zeitverlauf erleichtern.
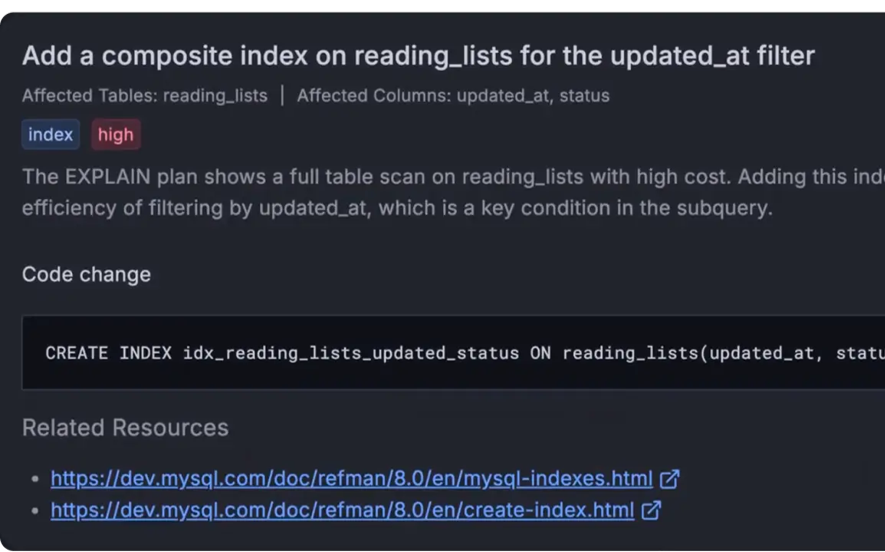
Fehlerbehebungen mit KI-generierter DDL bereitstellen
KI-gestützte Analysen heben Optimierungsmöglichkeiten wie fehlende Indizes und ineffiziente Queries hervor. Teams können sofort einsatzbereite SQL-Änderungen generieren und anwenden, was die Fehlerbehebung beschleunigt und den manuellen Tuning-Aufwand reduziert.
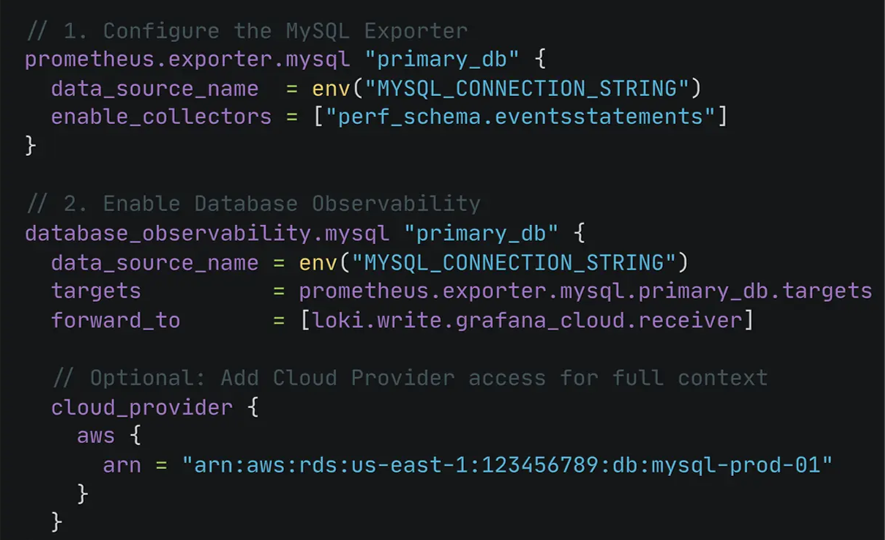
Einrichtung mit offenen Standards
Implementieren Sie Database Observability unter Verwendung offener Tools mit Alloy-Kollektoren für MySQL und PostgreSQL. Dieser Ansatz unterstützt Cloud-Datenbanken wie RDS, Aurora, CloudSQL und Azure Database und ermöglicht gleichzeitig den sicheren Umgang mit sensiblen Daten durch integrierte SQL-Redaction.
LGTM | Die Basis der Grafana Cloud Observability
Der LGTM-Stack bildet den Kern der Grafana Cloud und basiert auf Logs, Metrics, Traces sowie Grafana als Visualisierungsebene. Er bietet eine einheitliche Open-Source-Grundlage, um das Systemverhalten über Ihre gesamte Infrastruktur hinweg zu verstehen. Unterstützt durch Tools wie Loki, Tempo und das durch Grafana Mimir erweiterte Prometheus-Ökosystem, führt der Stack Telemetriedaten zusammen, sodass Teams Signale korrelieren und Probleme beheben können, ohne zwischen isolierten Systemen wechseln zu müssen. Dieser offene Ansatz vermeidet einen Vendor Lock-in und ermöglicht es Teams, Observability in komplexen Umgebungen konsistent zu skalieren. amasol entwirft und betreibt LGTM-basierte Observability-Setups, die strukturiert, zuverlässig und auf den tatsächlichen Betrieb Ihrer Systeme in der Produktion ausgerichtet sind.
Loki (Logs)
Loki speichert Logs als Streams von gelabelten Daten anstatt einer Volltextindizierung. Dies macht den Betrieb bei hoher Skalierung hocheffizient und ermöglicht dennoch die Suche im vollständigen Log-Inhalt, wenn dies erforderlich ist. Labels werden verwendet, um Queries einzugrenzen, was Noise reduziert und die Query-Performance verbessert.
Grafana (Visualization & Dashboard)
Grafana Cloud bietet den Visualisierungs- und Exploration-Layer für Observability-Daten. Sie verbindet Metriken, Logs und Traces aus beliebigen Quellen in Dashboards, die Querying, Alerting und Analysen unterstützen, ohne dass eine Datenmigration erforderlich ist.
Tempo (Traces)
Tempo speichert verteilte Traces ohne die Indizierung jedes einzelnen Spans, was eine kosteneffiziente Speicherung bei hohem Volumen ermöglicht. Es erlaubt Teams, Anfragen end-to-end zu verfolgen, Metriken aus Traces zu generieren und Latenz- oder Fehlerquellen über Services hinweg schnell zu identifizieren.
Mimir & Prometheus (Metrics)
Grafana Mimir erweitert Prometheus zu einem skalierbaren Langzeit-Metriksystem. Es unterstützt die Speicherung großer Mengen an Zeitreihendaten mittels Object Storage und ermöglicht so globale Sichtbarkeit, lange Aufbewahrungsfristen und schnelle PromQL-Queries über umfangreiche Umgebungen hinweg.
Überspringen Sie die Lernkurve und vereinfachen Sie Ihren Workflow
Nutzen Sie das KI-gestützte Setup und Natural Language Queries, um Dashboards schneller zu erstellen und Daten effizienter zu explorieren. Dies verkürzt die Onboarding-Zeit und macht komplexe Observability-Workflows für Anwender*innen auf jedem Level zugänglich.
Beschleunigen Sie die Root-Cause-Analyse durch agentische Untersuchungen
Assistant Investigations nutzt KI-gestützte Korrelationen über Ihren gesamten Stack hinweg, um Anomalien frühzeitig zu erkennen und das Verständnis von Vorfällen zu beschleunigen. Durch die Nutzung kontextbezogener Einblicke des SRE-Agents und des Grafana Cloud Knowledge Graphs können Teams Root-Causes schneller identifizieren und sich auf die Behebung der Auswirkungen konzentrieren, anstatt Zeit mit manueller Triage zu verlieren.
Ermöglichen Sie Ihrem gesamten Team, aktiv zu werden
Brechen Sie Wissenssilos auf, indem Sie Teams ermöglichen, durch KI-generierte Insights mit Observability-Daten zu interagieren. Automatisieren Sie Routineaufgaben wie Incident-Summaries, Log-Erklärungen und erste Fehleranalysen, um die kognitive Last zu reduzieren und die Effizienz der Reaktion zu verbessern.
Skalieren Sie sicher mit den Tools, die Sie bereits nutzen
Verwalten Sie Zugriff und Governance durch rollenbasierte Kontrollen, während die Compliance mit Standards wie SOC 2, GDPR und CCPA gewahrt bleibt. Direkt in die Grafana Cloud integriert, unterstützt der Assistant die sichere Zusammenarbeit über Slack, MCP-Server und das Grafana-Interface, ohne Workflows zu unterbrechen.
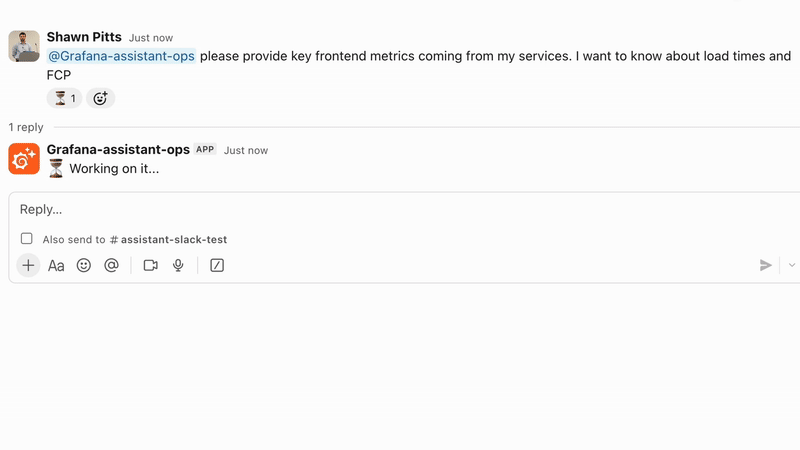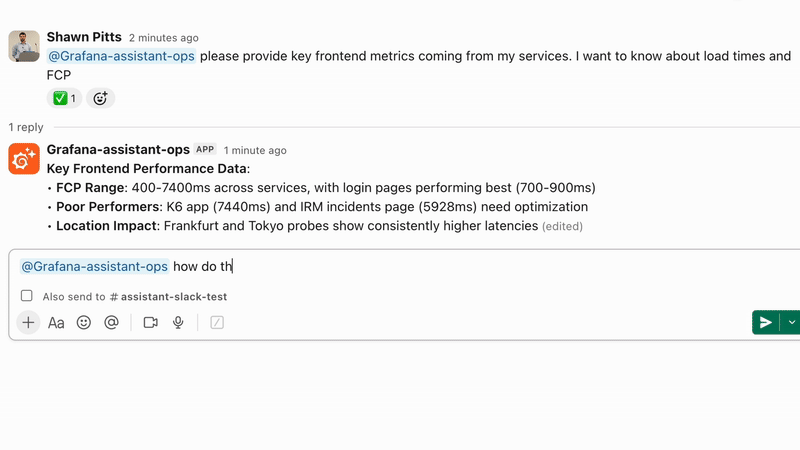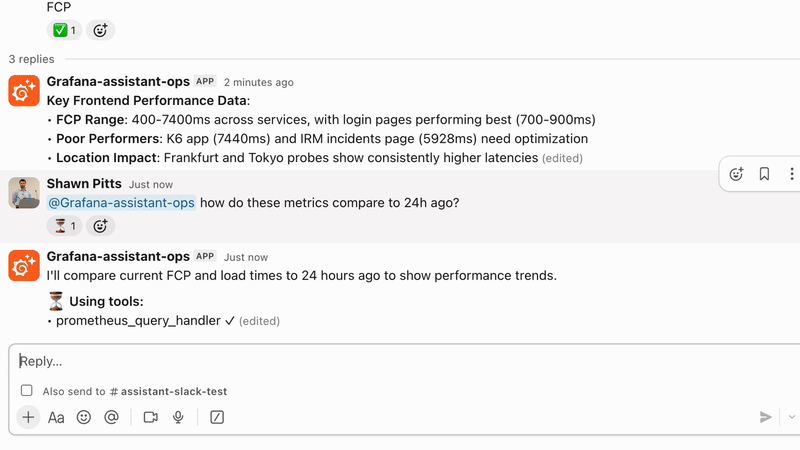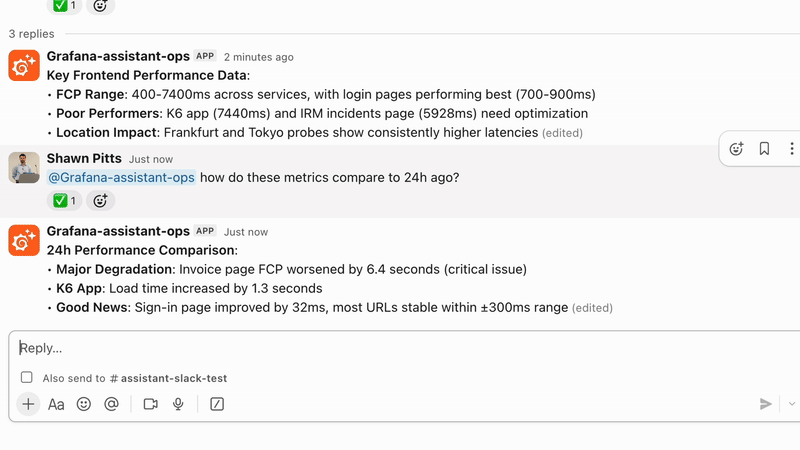
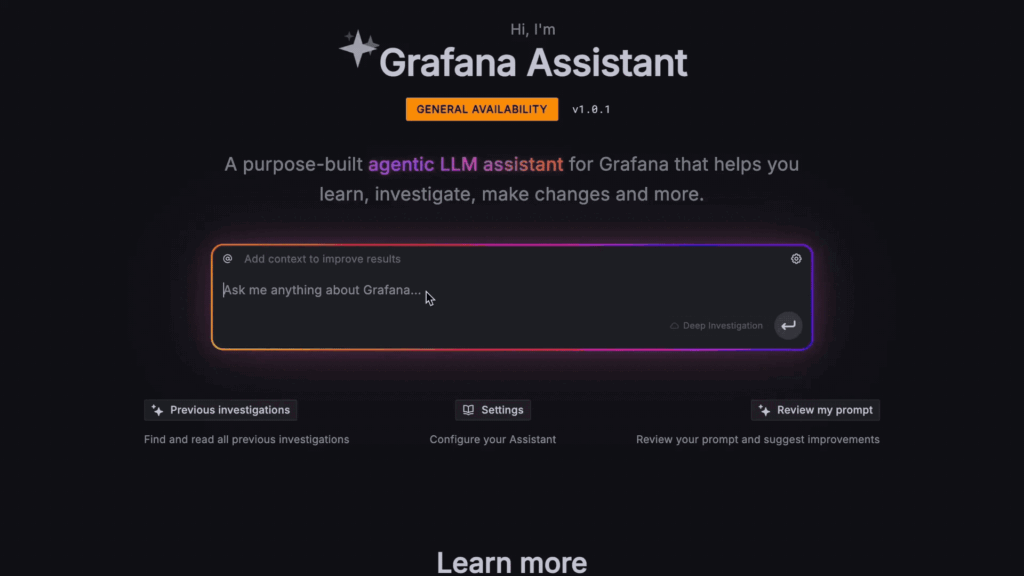
Grafana AI Assistant | Für den Fall, dass Sie eine schnellere und smartere Observability benötigen
Grafana Cloud beinhaltet einen AI Assistant, mit dem Sie Observability-Daten unter Verwendung natürlicher Sprache abfragen und explorieren können. Er kann Queries generieren, Dashboards erstellen und Untersuchungen über Logs, Metrics und Traces hinweg unterstützen, ohne dass fortgeschrittene Query-Kenntnisse erforderlich sind. Er hilft Teams dabei, schneller von der rohen Telemetrie zum Verständnis von Problemen zu gelangen, indem er relevante Signale aufzeigt und Anomalien direkt in der Grafana Cloud erklärt. Bei amasol unterstützen wir Sie dabei, den Grafana Assistant in reale Workflows zu integrieren, um sicherzustellen, dass Teams ihn effektiv für ein schnelleres Troubleshooting und eine einfachere Interaktion mit Observability-Daten nutzen können.


Grafana | Visualisieren Sie alles. Observieren Sie alles.
Grafana ermöglicht es Ihnen, Ihre Daten abzufragen, zu visualisieren und zu überwachen, ganz gleich, wo diese liegen. Sie können flexible Dashboards erstellen, um Informationen zu explorieren, das Systemverhalten zu verfolgen und Insights in Ihren Teams zu teilen. Gemeinsam mit amasol helfen wir Ihnen, diese Funktionen in ein funktionierendes Observability-Setup zu verwandeln. Wir konzipieren und implementieren Ihre Grafana-Umgebung, binden Ihre Datenquellen an und stellen sicher, dass Ihre Dashboards die Systeme widerspiegeln, die Sie tatsächlich betreiben, damit Ihre Teams echte Klarheit gewinnen und nicht bloß Diagramme erhalten.
Verstehen Sie Ihre Systeme, ohne Ihre Daten verschieben zu müssen
Grafana ist in der Lage, Ihre vorhandenen Daten dort zu visualisieren und zu explorieren, wo sie sich befinden, ohne dass eine Migration erforderlich ist. Es ist nicht notwendig, Daten in einen Backend-Speicher oder eine Datenbank eines Drittanbieters zu übertragen.
Geben Sie jedem Team die Sichtbarkeit, die es benötigt
Daten sollten nicht auf ein einzelnes Team beschränkt sein. Grafana macht es für alle einfach, auf die benötigten Informationen zuzugreifen und diese zu nutzen, was Teams hilft, mit einem gemeinsamen Kontext zu arbeiten, und Datensilos reduziert.
Verwandeln Sie Daten in handfeste Insights
Erstellen Sie Dashboards, die genau Ihren Anforderungen entsprechen, indem Sie flexible Queries und Transformationen nutzen. Grafana ermöglicht es Ihnen, Daten so aufzubereiten und zu präsentieren, dass sie leichter zu verstehen sind und direktes Handeln ermöglichen.
Explorieren und visualisieren Sie Ihre Daten
Warum Grafana in der Grafana Cloud nutzen?
Plugins
Vernetzen Sie Ihre Tools und Ihre Teams mit Grafana-Plugins. Data-Source-Plugins binden bestehende Datenquellen über APIs an und stellen die Daten in Echtzeit dar, ohne dass Sie Ihre Daten migrieren oder neu erfassen müssen.
Alerts
Mit Grafana Alerting können Sie all Ihre Alerts in einer einzigen, einfachen Benutzeroberfläche erstellen, verwalten und stummschalten, was es Ihnen ermöglicht, all Ihre Alerts problemlos zu konsolidieren und zentralisieren.
Transformations
Transformationen ermöglichen es Ihnen, Umbenennungen, Zusammenfassungen, Kombinationen und Berechnungen über verschiedene Queries und Datenquellen hinweg durchzuführen.
Annotations
Annotieren Sie Graphen mit detailreichen Ereignissen aus verschiedenen Datenquellen. Das Hovern über Ereignisse zeigt Ihnen die vollständigen Metadaten und Tags des Events an.
Panel editor
Der Panel-Editor macht es einfach, all Ihre Panels zu konfigurieren, anzupassen und zu explorieren, mit einer konsistenten Benutzeroberfläche zur Festlegung von Datenoptionen über all Ihre Visualisierungen hinweg.
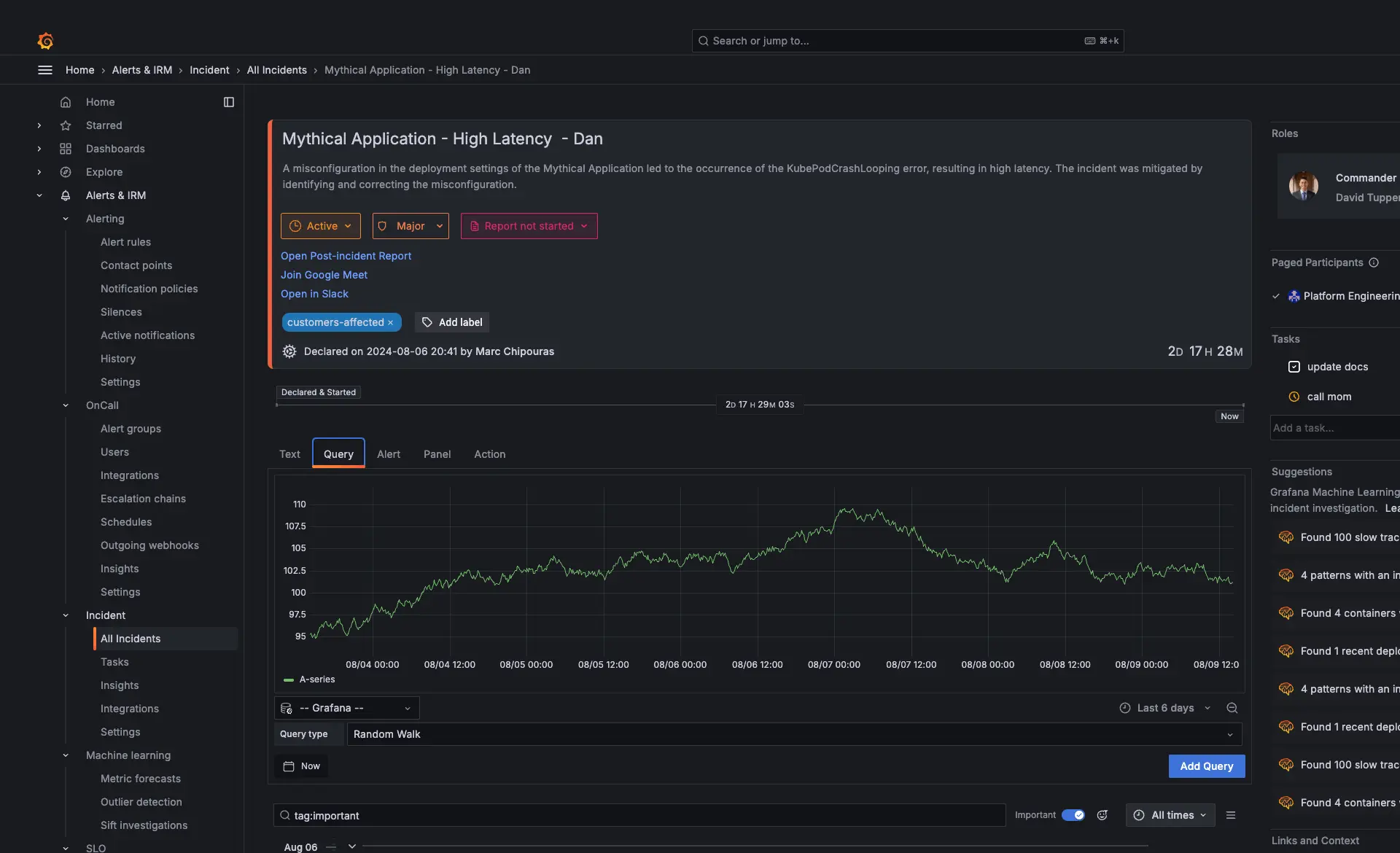
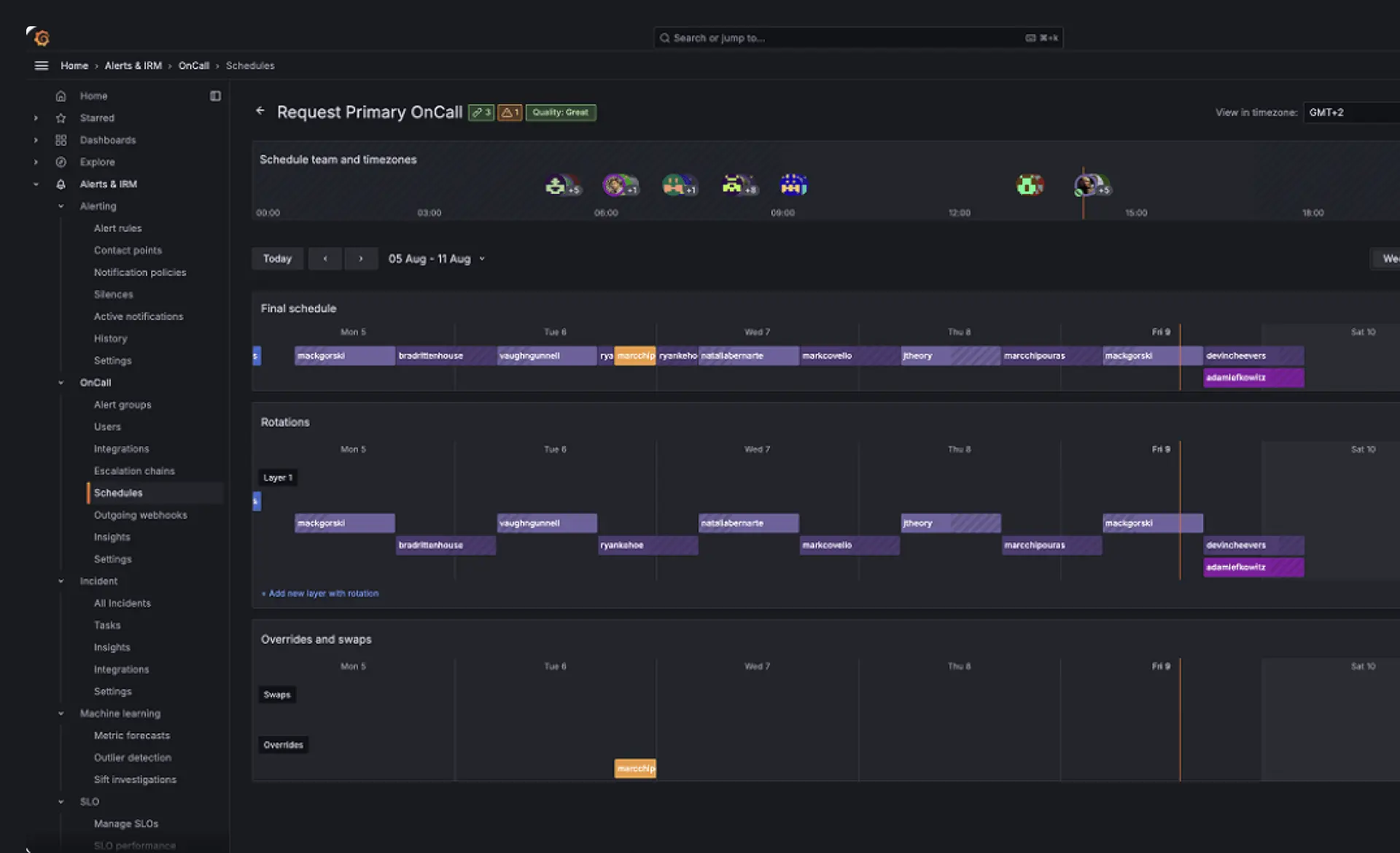
Incident Response & Management (IRM) | Verwandeln Sie Alerts in handfeste Insights
Grafana Cloud IRM unterstützt Sie bei der Verwaltung von Incidents durch einen einzigen, einheitlichen Workflow für Alerts, On-Call-Scheduling und Response. Es führt Alerting und Incident-Koordination zusammen, damit Teams Probleme effizienter erkennen, weiterleiten und beheben können. Gemeinsam mit amasol helfen wir Ihnen, dieses Setup Ende-zu-Ende zu konzipieren und zu betreiben, indem wir das Alert-Routing konfigurieren, On-Call-Prozesse strukturieren und Incident-Workflows in Ihre bestehenden Systeme integrieren, damit Ihre Teams schneller und reibungsloser reagieren können.
Reagieren Sie schnell und sicher auf Probleme
Passen Sie Workflows so an, dass die richtigen Expert*innen über den richtigen Kontext verfügen, um Probleme schnell zu beheben und eine 24/7-Abdeckung zu gewährleisten.
Beseitigen Sie Unklarheiten vor, während und nach Incidents
Zentralisieren Sie die Kommunikation, automatisieren Sie manuelle Aufgaben und behalten Sie den Fortschritt von Incidents von Beginn bis zur Lösung klar im Blick.
Zahlen Sie nur für aktive Nutzer*innen, sonst nichts
Kosten skalieren nur, wenn Ingenieur*innen Grafana Cloud IRM aktiv nutzen.
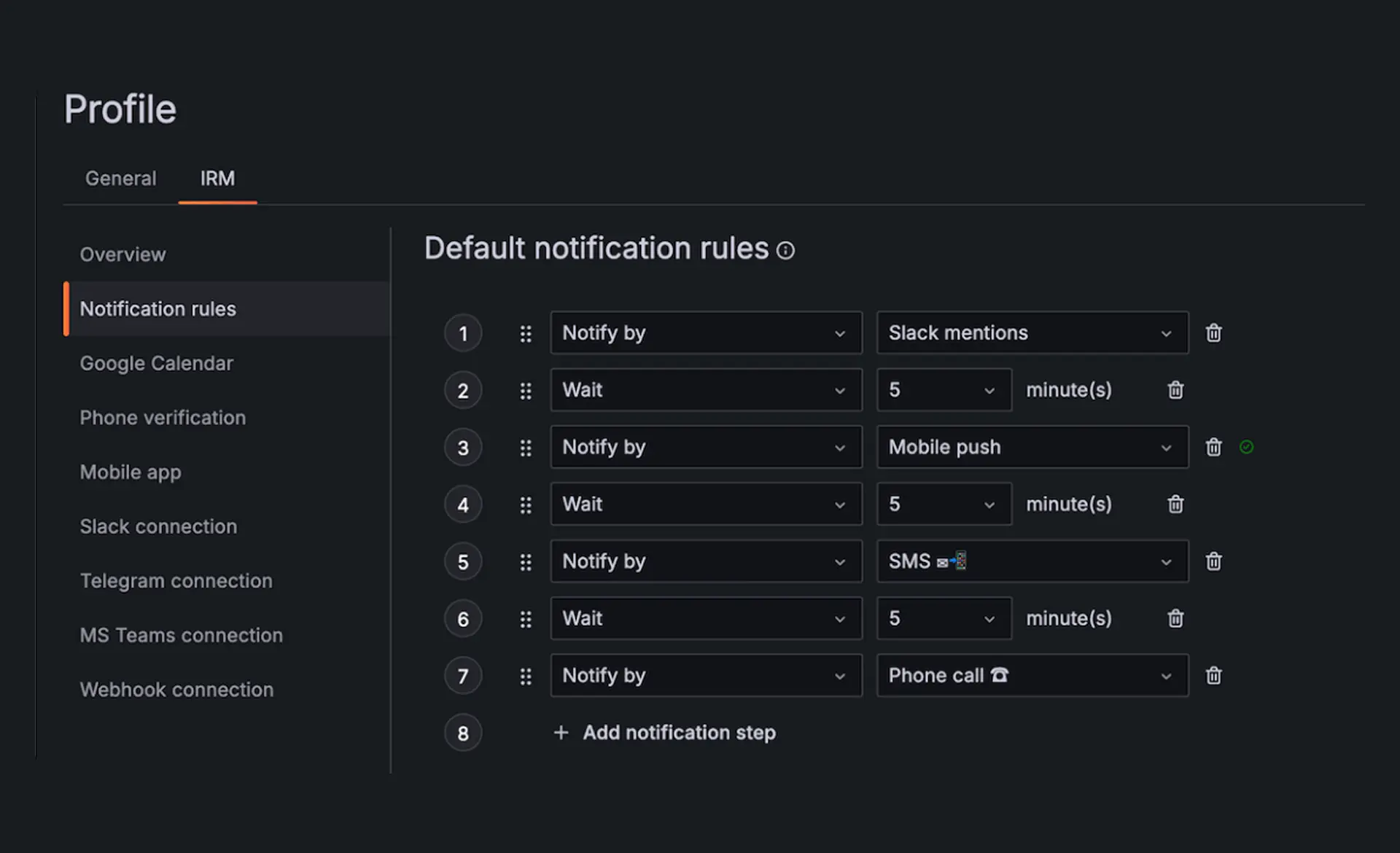
Benachrichtigen Sie die richtigen Expert*innen zum richtigen Zeitpunkt
Alerts erreichen die richtigen Teams basierend auf Rollen, Verantwortlichkeiten und dem On-Call-Kontext. Benachrichtigungen werden über die Tools zugestellt, die Teams bereits nutzen, einschließlich Slack, Microsoft Teams, Mobile Apps, SMS, E-Mail und Anrufen. Alerts werden geroutet, um Noise zu reduzieren und sicherzustellen, dass die relevanten Personen benachrichtigt werden. Ingenieur*innen können Incidents direkt aus ihrem Kommunikationskanal heraus bestätigen, eskalieren oder beheben, unterstützt durch automatisierte Eskalationsketten, die Verzögerungen bei der Reaktion eliminieren.
Eine Single Source of Truth für Incidents
Alle Incident-Daten werden in einer einzigen Timeline zentralisiert, die wichtige Ereignisse, Entscheidungen und Maßnahmen während des gesamten Incident-Lifecycles erfasst. Dies bietet eine klare, strukturierte Sicht darauf, was wann passiert ist. Post-Incident-Reviews können direkt aus dieser Timeline erstellt werden, wodurch ein konsistenter Datensatz für Lerneffekte und Prozessverbesserungen entsteht. Im Laufe der Zeit können Teams diese Historie nutzen, um Bottlenecks zu identifizieren und Response-Workflows zu verbessern.
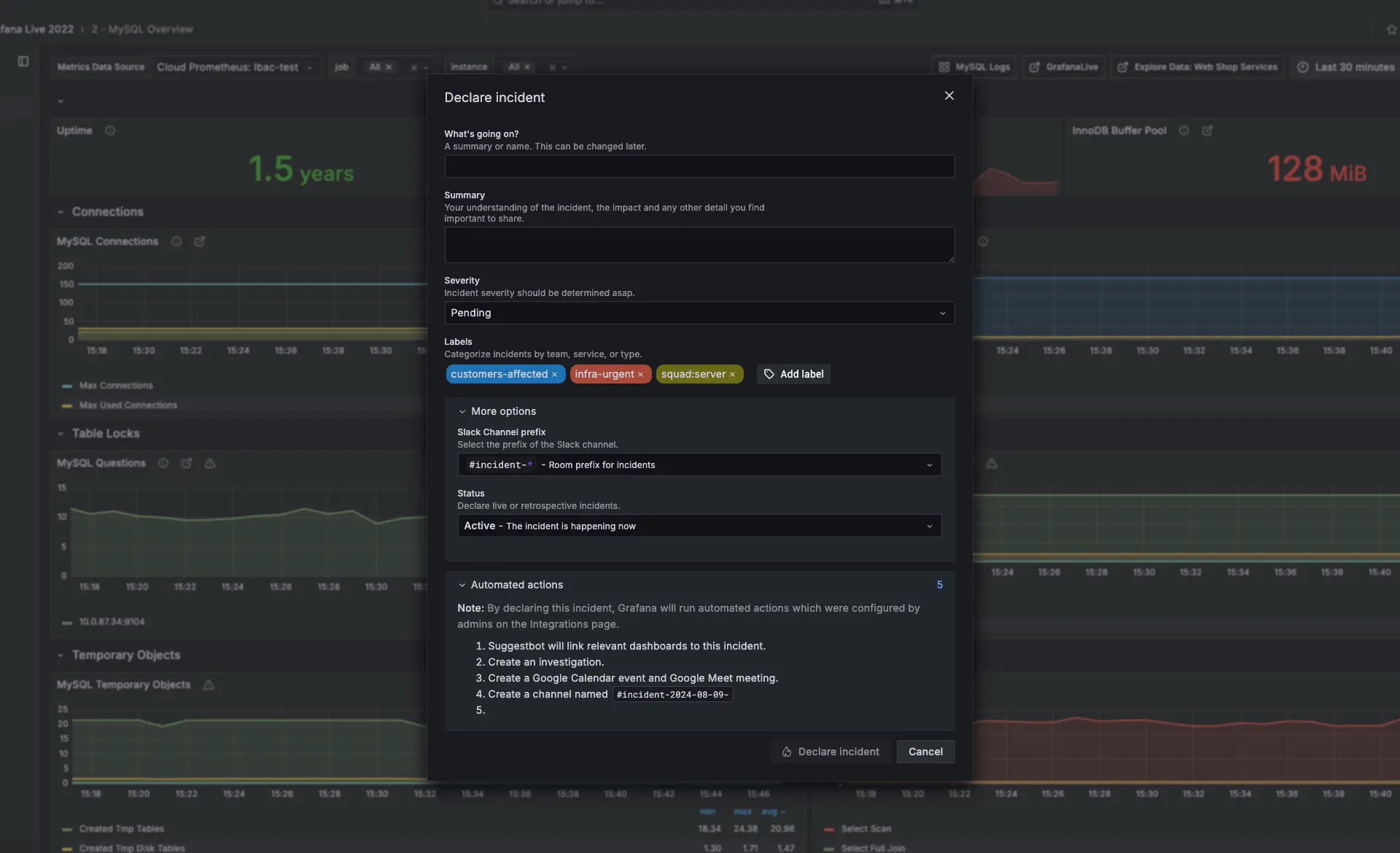
Reagieren Sie auf Incidents direkt aus Ihrem Observability-Stack heraus
Incidents können direkt aus Grafana-Dashboards heraus initiiert werden, sobald Anomalien oder Performance-Probleme erkannt werden. Dies ermöglicht es Teams, ohne Tool-Wechsel von der Erkennung zur Response überzugehen. IRM lässt sich in Systeme wie Jira, ServiceNow und GitHub integrieren, um in bestehende Workflows zu passen und gleichzeitig einen konsistenten Incident-Prozess beizubehalten. Das Tracking von Incident-Mustern im Zeitverlauf hilft Teams dabei, Response-Strategien zu verfeinern und die operative Reife zu verbessern.
IRM überall und jederzeit mit der Mobile App
Die Mobile Experience bietet Echtzeit-Incident-Awareness durch kontextbezogene Push-Benachrichtigungen. Ingenieur*innen können Incidents direkt von ihrem Gerät aus bestätigen, eskalieren oder beheben. On-Call-Schedules, Schichtwechsel und Teamverfügbarkeiten können von unterwegs verwaltet werden, was eine kontinuierliche Koordination auch außerhalb der Arbeitszeiten sicherstellt. Kritische Alerts können Benachrichtigungseinstellungen umgehen, wenn sofortiges Handeln erforderlich ist.
Warum sollten Sie Grafana Cloud für das Incident Response Management (IRM) nutzen?
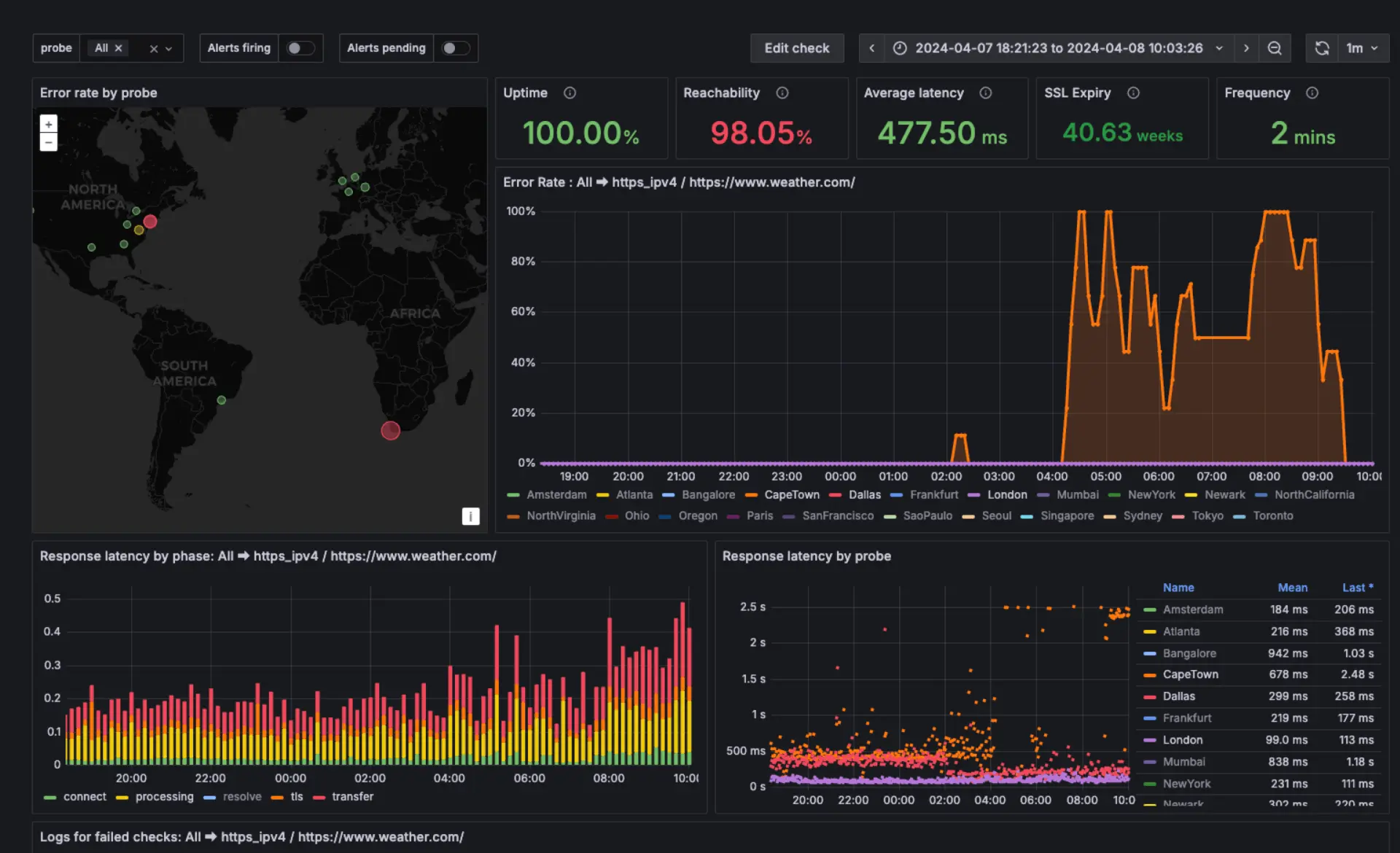
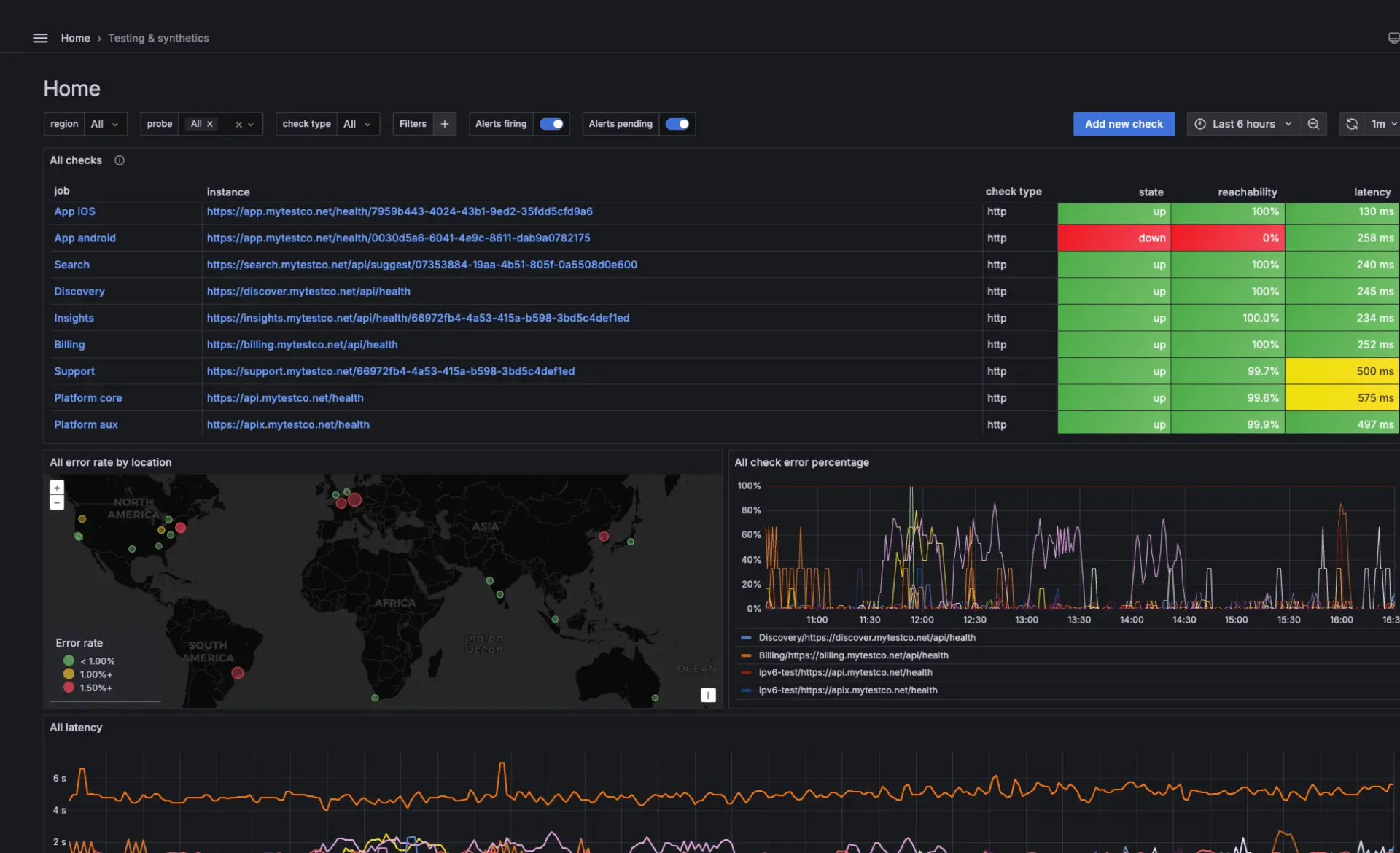
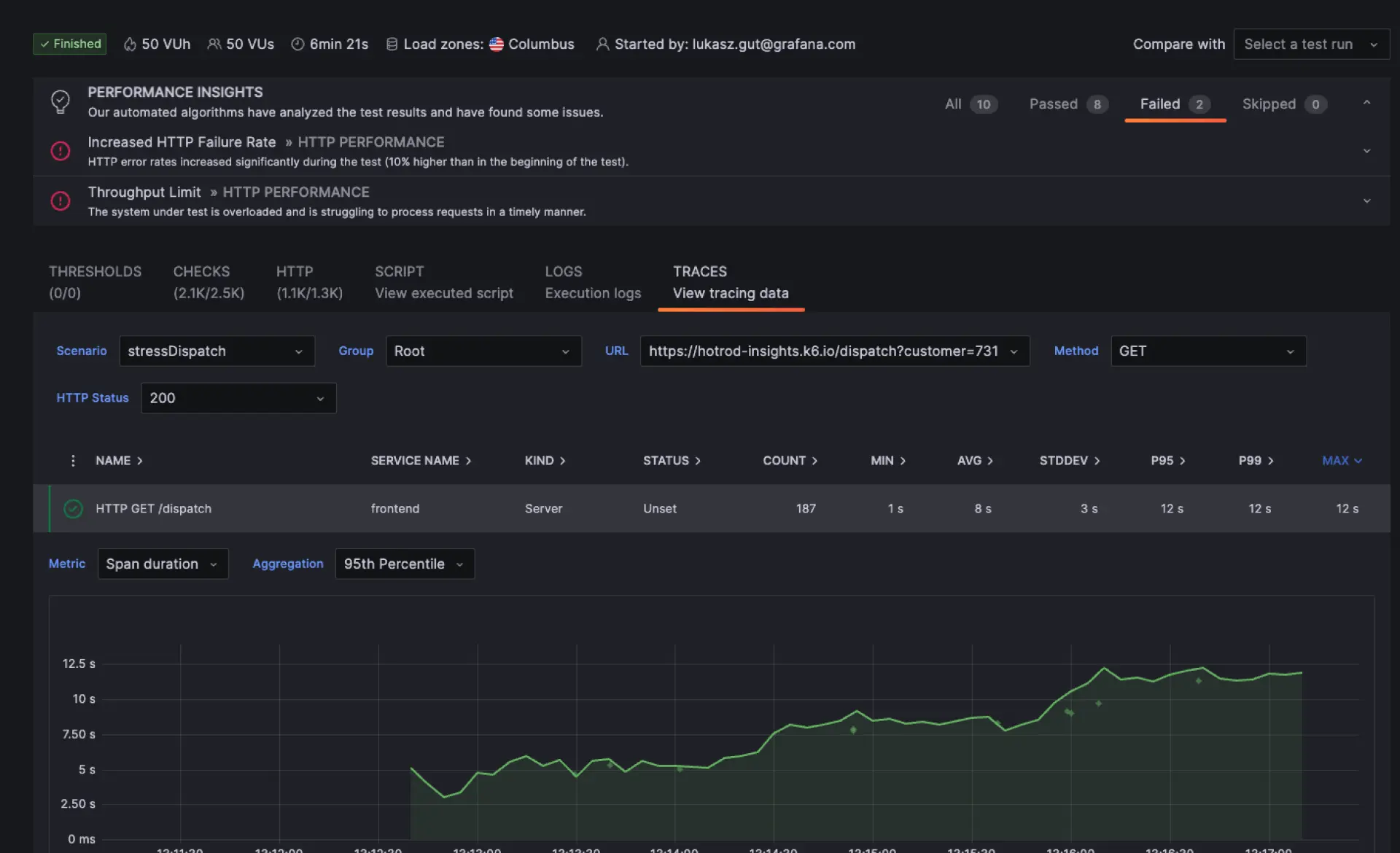
Synthetic monitoring | Fake Nutzer*innen, echte Ergebnisse
Grafana Cloud Synthetic Monitoring, powered by k6, testet kontinuierlich Websites, APIs und kritische User Journeys von Standorten auf der ganzen Welt aus, um Ausfälle und Performance-Probleme frühzeitig zu identifizieren. Gemeinsam mit amasol helfen wir Ihnen dabei, die wichtigsten User Journeys zu definieren, aussagekräftige synthetische Checks zu implementieren und diese in Ihr Observability-Setup zu integrieren, damit Sie Probleme erkennen können, bevor sie Auswirkungen auf Nutzer*innen haben, und zuverlässige digitale Services aufrechterhalten können.
Behalten Sie Ihre SLOs im Blick
Grafana Cloud Synthetic Monitoring führt Checks über verschiedene Protokolle hinweg aus, einschließlich DNS, HTTP, HTTPS, TCP und Ping, um die Systemverfügbarkeit und Performance zu validieren. Tests können von globalen Probe-Standorten aus ausgeführt werden, um reale Nutzerzugriffsmuster abzubilden, wobei Ausfälle direkt in Grafana Cloud visualisiert und gemeldet werden.
Validieren Sie kritische User Journeys
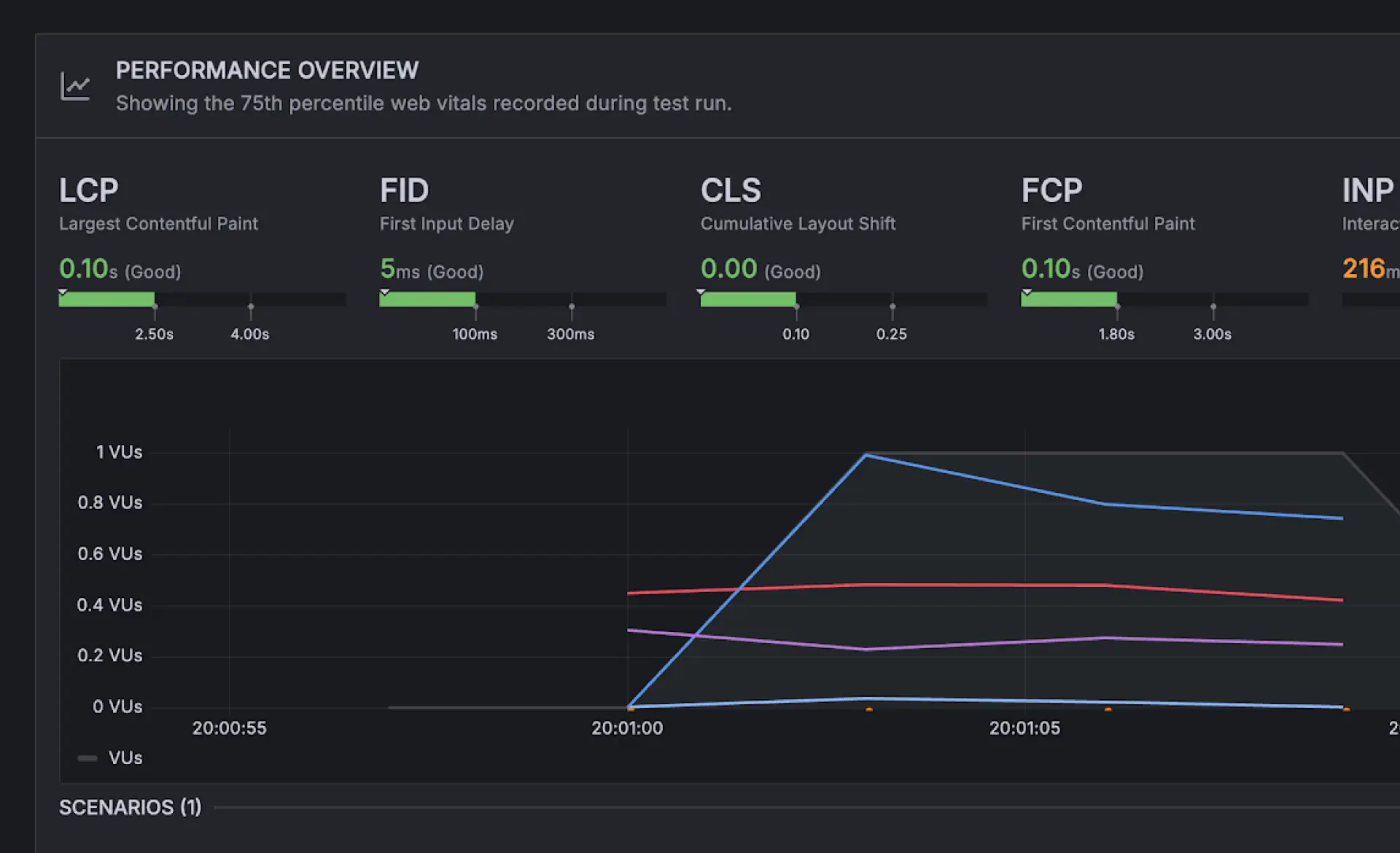
Browserbasierte Tests simulieren reale Nutzerinteraktionen, um Performance-Indikatoren wie Web Vitals und das Seitenladeverhalten zu messen. Dies hilft Teams dabei, Bottlenecks in End-to-End-Workflows zu identifizieren und zu verstehen, wie sich Anwendungsänderungen auf die reale User Experience über verschiedene Geräte und Umgebungen hinweg auswirken.
Shift Left durch Reliability Testing as Code
Synthetische Checks können mit JavaScript und der k6 API definiert werden, was es Teams ermöglicht, die Testlogik über Development-Workflows hinweg zu versionieren, wiederzuverwenden und zu automatisieren. Diese Checks können zusammen mit dem Applikationscode gespeichert und über CI-Pipelines oder Infrastructure-as-Code-Tools wie Terraform bereitgestellt werden.
Untersuchen und beheben Sie Probleme schneller
Synthetische Ergebnisse werden in Grafana Cloud mit Metriken, Logs und Traces kombiniert, um eine schnellere Root-Cause-Analysis zu unterstützen. Teams können integrierte Dashboards nutzen oder benutzerdefinierte Ansichten erstellen, um Ausfälle im Kontext zu verstehen und Performance-Trends im Zeitverlauf zu verfolgen.
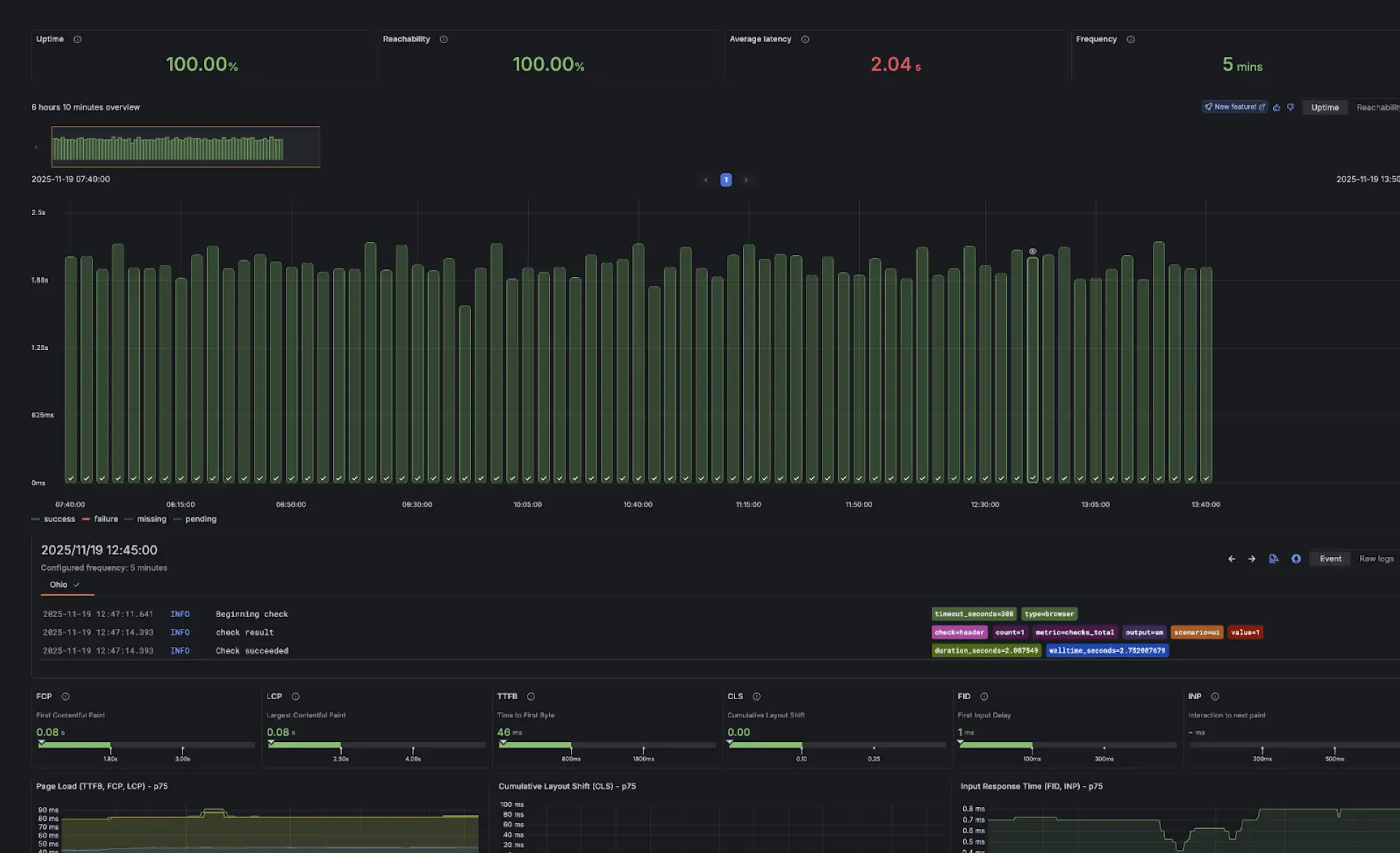
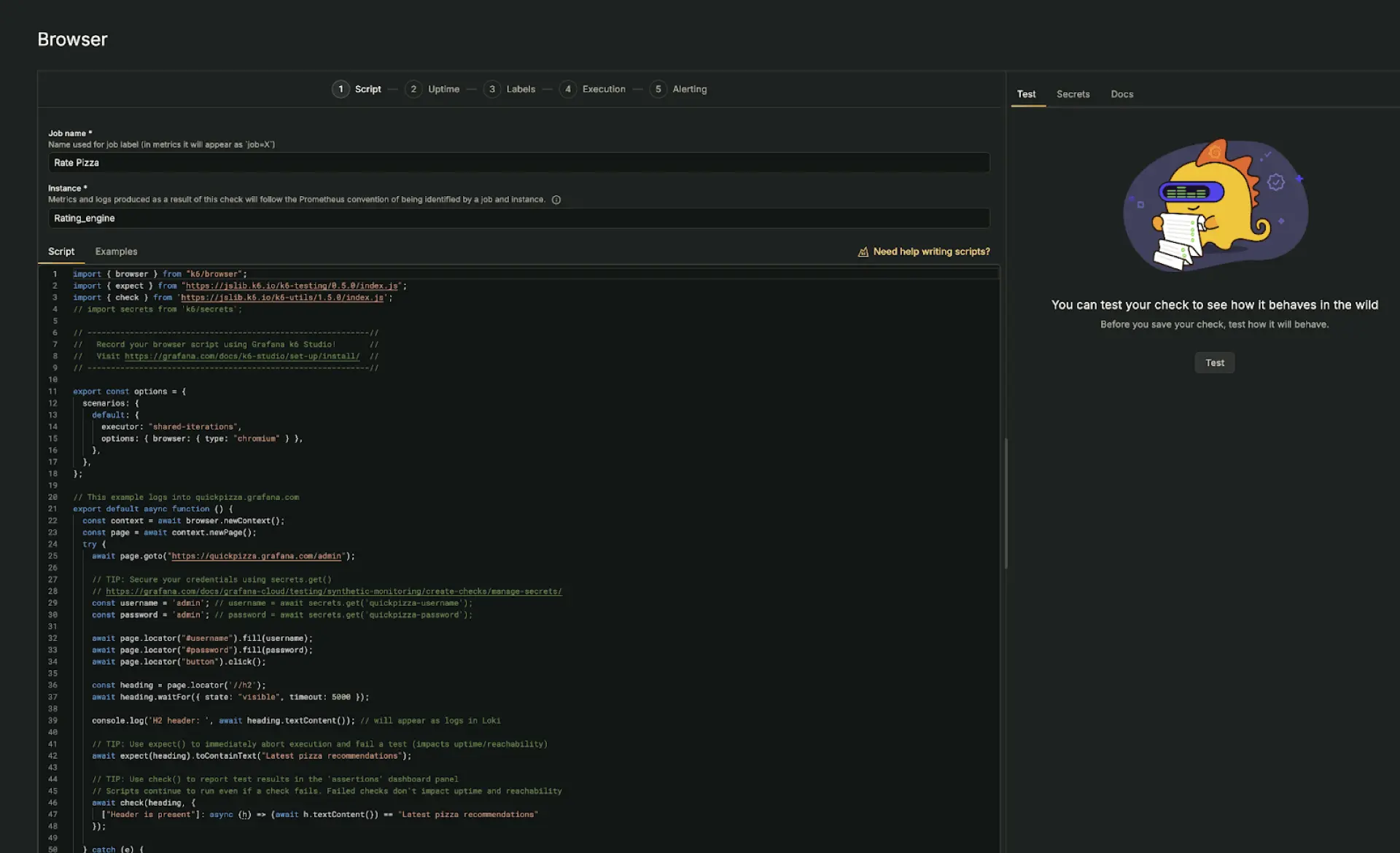
Verbessern Sie die Reliability durch Shift-Left-Testing
Grafana Cloud ermöglicht Performance-Testing frühzeitig im Entwicklungsprozess durch die Nutzung von k6 APIs, CLI und JavaScript direkt in Workflows und IDEs. Tests können über CI-Pipelines automatisiert und über die Web-App geplant werden, wobei SLOs als Erfolgskriterien dienen. Realistische Traffic-Muster wie Smoke-, Soak- und Load-Tests helfen dabei, das Systemverhalten unter Realbedingungen vor dem Deployment zu validieren.
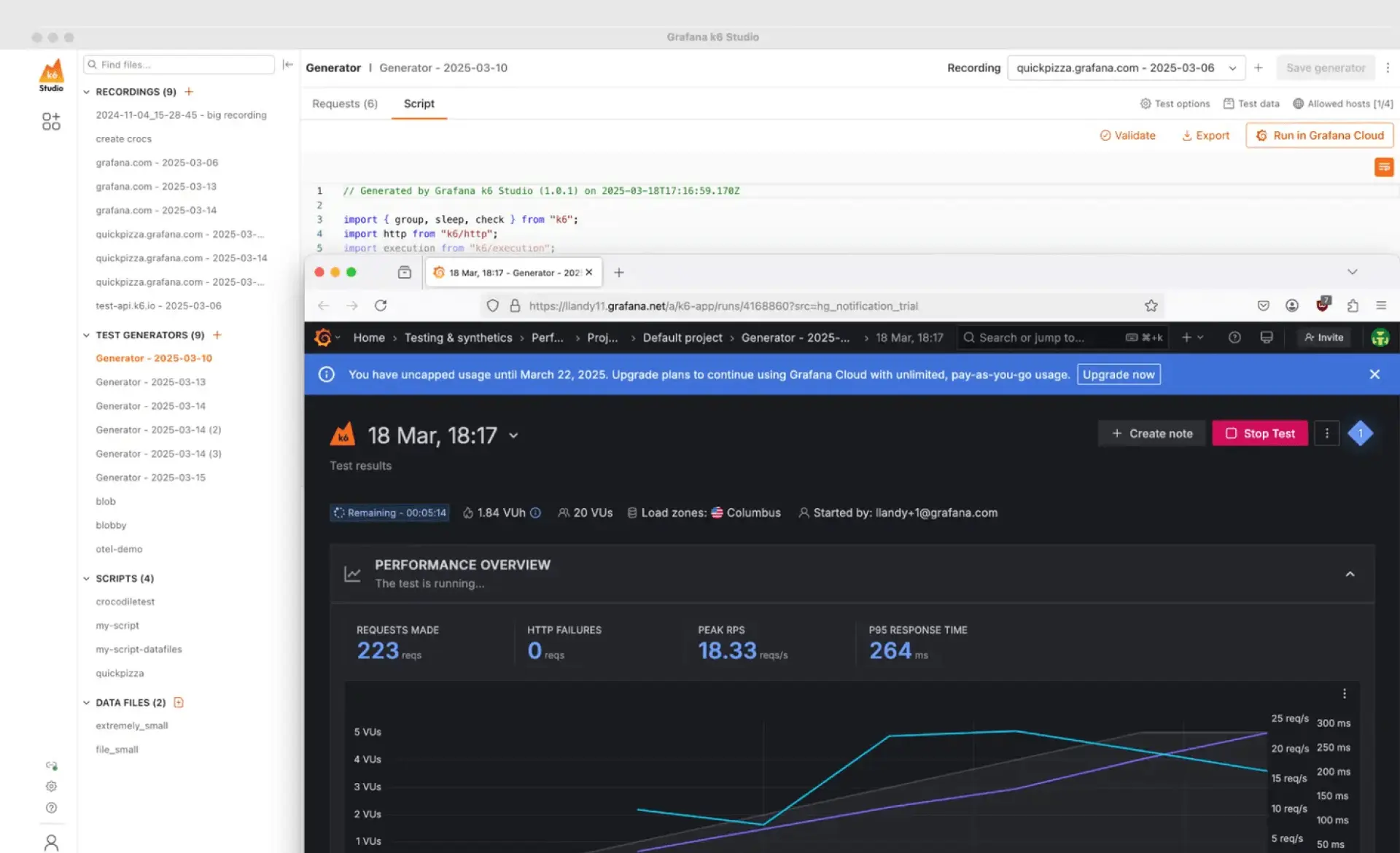
Vereinfachen Sie die Testerstellung
Tests können schnell erstellt werden, indem User-Flows mit k6 Studio in Skripte umgewandelt werden. Reale User Journeys können aufgezeichnet, verfeinert und in Grafana Cloud oder lokal mit k6 ausgeführt werden. Skripte lassen sich zudem visuell bearbeiten und debuggen, was es einfacher macht, die Testlogik und das Verhalten während der Entwicklung zu validieren.
Kombinieren Sie Frontend- und Backend-Performance-Testing
Browserbasierte Tests mit der k6 API simulieren reale Nutzerinteraktionen wie Klicks, Tippen und Navigation, während gleichzeitig Performance-Metriken erfasst werden. Tests auf Protokollebene und Browser-Ebene können gemeinsam ausgeführt werden, um eine vollständige Ansicht der Applikationsperformance zu erhalten. Die Testergebnisse umfassen Web Vitals, Interaktions-Timelines und Screenshots, um ein schnelleres Debugging zu unterstützen.
Führen Sie skalierbare Cloud-Tests aus
Performance-Tests können mit Grafana Cloud global in mehr als 20 geografischen Regionen ausgeführt werden. Private Load Zones ermöglichen das sichere Testen interner Systeme, während die Cloud-Infrastruktur groß angelegte Lastszenarien mit hoher Parallelität und hohem Request-Volumen zur Stress-Validierung unterstützt.
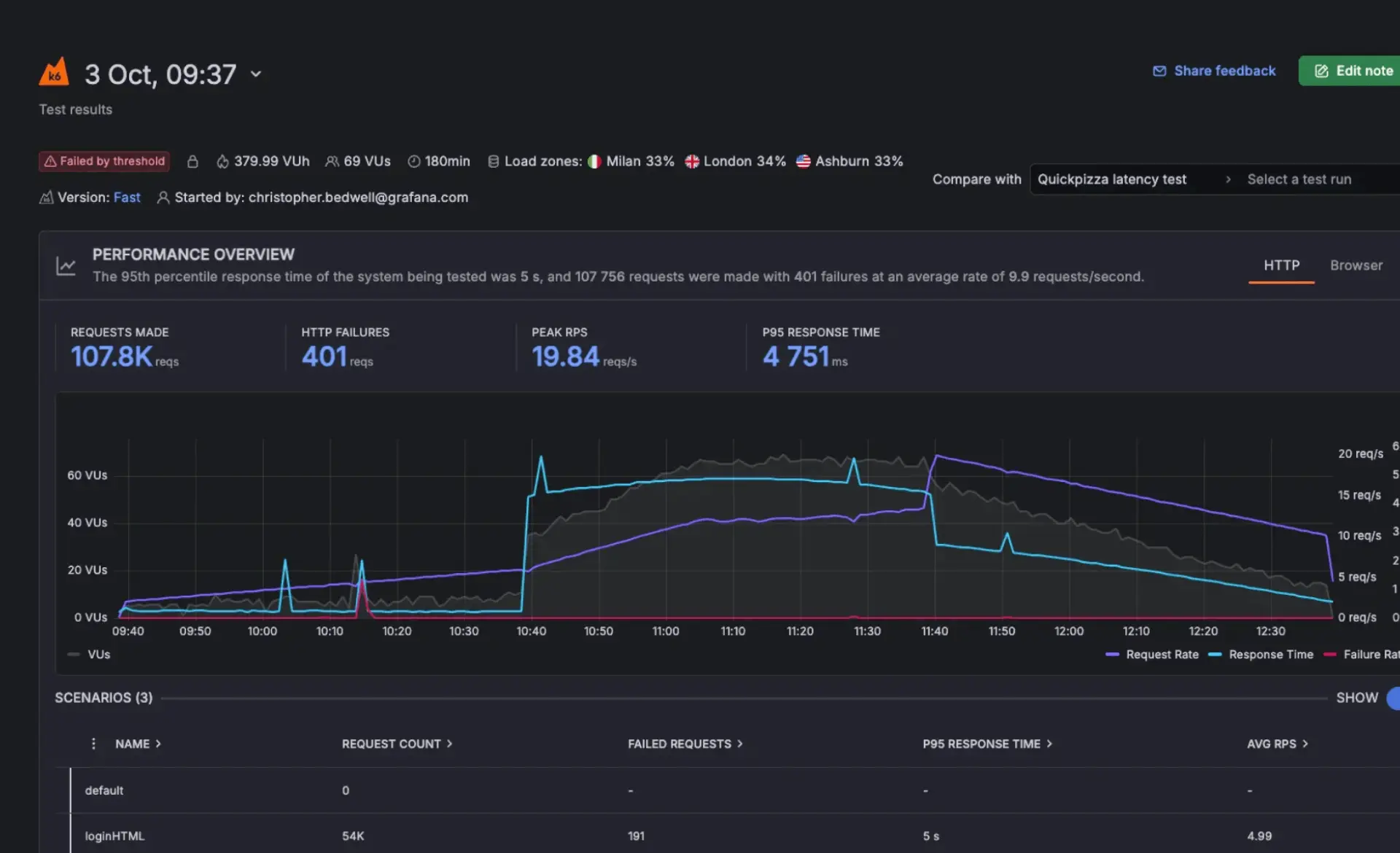
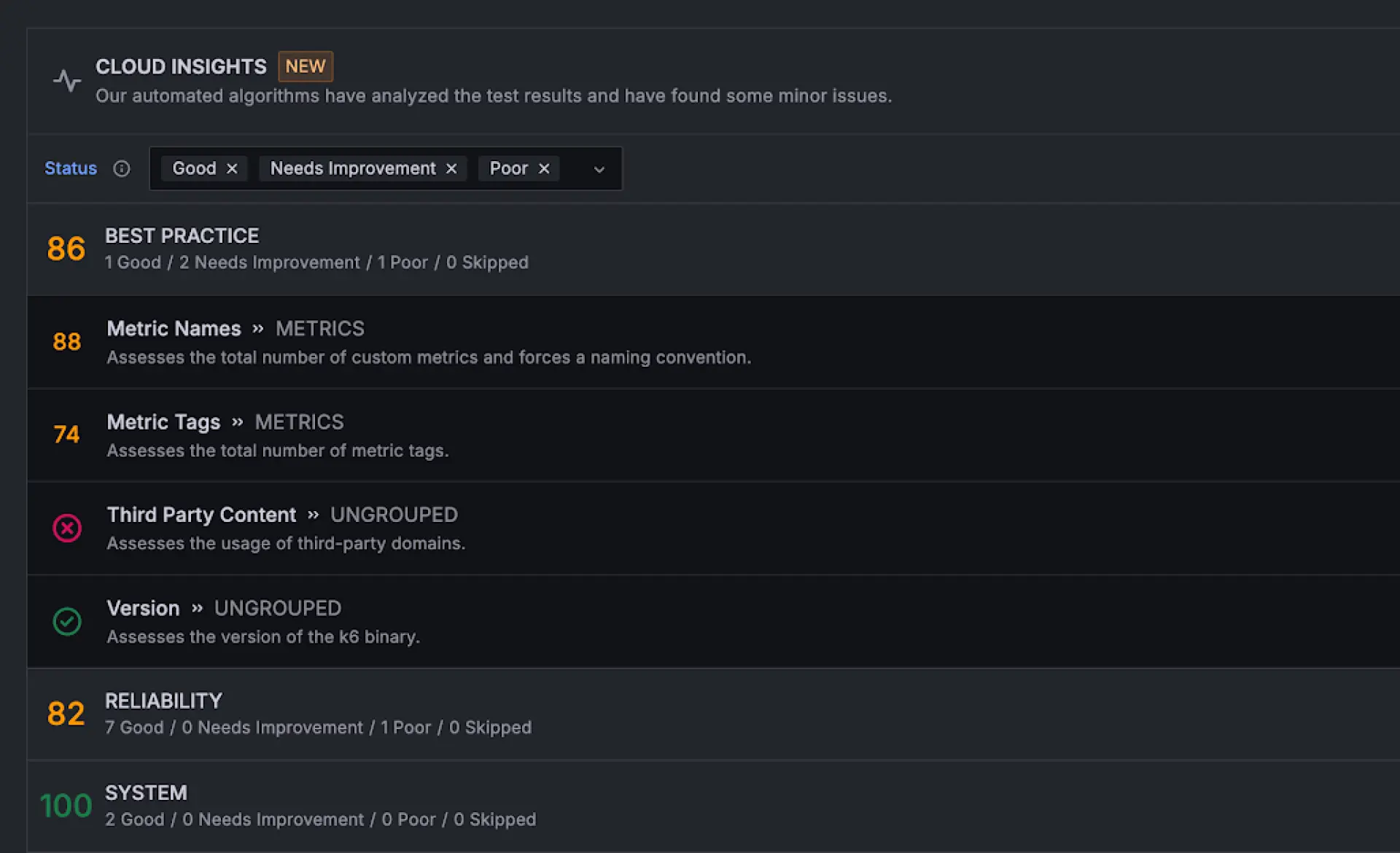
Analysieren Sie Performance-Testergebnisse
Cloud Insights hebt Performance-Probleme automatisch hervor und vergleicht Ergebnisse über verschiedene Testläufe hinweg, um Regressionen im Zeitverlauf zu erkennen. Teams können Ergebnisse direkt in Grafana Cloud Dashboards untersuchen und k6-Visualisierungen zu bestehenden Observability-Ansichten hinzufügen, um Performance-Trends kontinuierlich zu überwachen.
Korrelieren Sie Performance-Testing und Observability
Performance-Testergebnisse können zusammen mit Metriken, Logs, Traces und Profilen innerhalb von Grafana Cloud analysiert werden. Dies ermöglicht es Teams, direkt von den Testergebnissen zur Root-Cause-Analysis überzugehen und Bottlenecks auf Systemebene zu identifizieren, ohne das Tool wechseln zu müssen.
Performance & load testing | Testen Sie Systemlimits, bevor Nutzer*innen es tun
Basierend auf k6 unterstützt Grafana Teams dabei, realen Traffic zu simulieren und das Systemverhalten unter Last über APIs, Services und User Flows hinweg zu messen. Tests werden als Code verfasst und können als Teil von CI/CD-Pipelines ausgeführt werden, um die Performance vor Releases zu validieren und Regressionen frühzeitig zu erkennen. Die Ergebnisse werden zusammen mit Metrics, Logs und Traces in der Grafana Cloud analysiert. Dies ermöglicht es Teams, das Lastverhalten direkt mit der Systemperformance zu verknüpfen und Engpässe unter Stress schnell zu identifizieren. Berater*innen von amasol unterstützen Teams dabei, aussagekräftige Lasttests zu konzipieren, diese in Entwicklungs-Workflows zu integrieren und sicherzustellen, dass die Ergebnisse unmittelbar handlungsrelevant sind.
Grafana-Lösungen
KI-gestützte Beobachtbarkeit
Nutzen Sie KI, um Anomalien, Muster und relevante Signale in Ihren Telemetriedaten aufzudecken und Teams dabei zu unterstützen, Probleme schneller zu erkennen und zu verstehen.
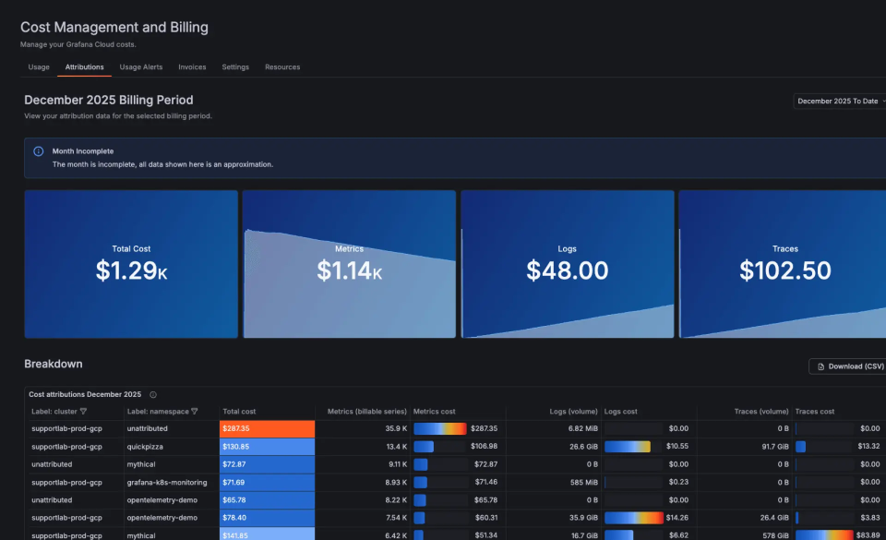
Kostenmanagement & Optimierung
Reduzieren Sie Observability-Ausgaben durch die Kontrolle des Datenvolumens, das Filtern von Rauschen und die Fokussierung auf hochwertige Signale bei Metriken, Logs und Traces.
Datenkorrelation & Root-Cause-Analysis
Verknüpfen Sie Logs, Metriken und Traces, um Abhängigkeiten aufzudecken und die Root-Cause von Performance-Problemen oder Systemausfällen schnell zu identifizieren.
Nativer OpenTelemetry-Support
Erfassen und verarbeiten Sie Telemetriedaten unter Verwendung offener Standards, um Flexibilität, Portabilität und eine nahtlose Integration über verschiedene Umgebungen hinweg zu gewährleisten.
Sicherheits- & Zugriffskontrolle
Schützen Sie Observability-Daten mit rollenbasierter Zugriffskontrolle, feingranularen Berechtigungen und sicherer Datenhandhabung über Teams und Umgebungen hinweg.
Governance & compliance
Behalten Sie die Kontrolle und Auditierbarkeit über Telemetriedaten bei, um interne Richtlinien und externe regulatorische Anforderungen skalierbar zu erfüllen.
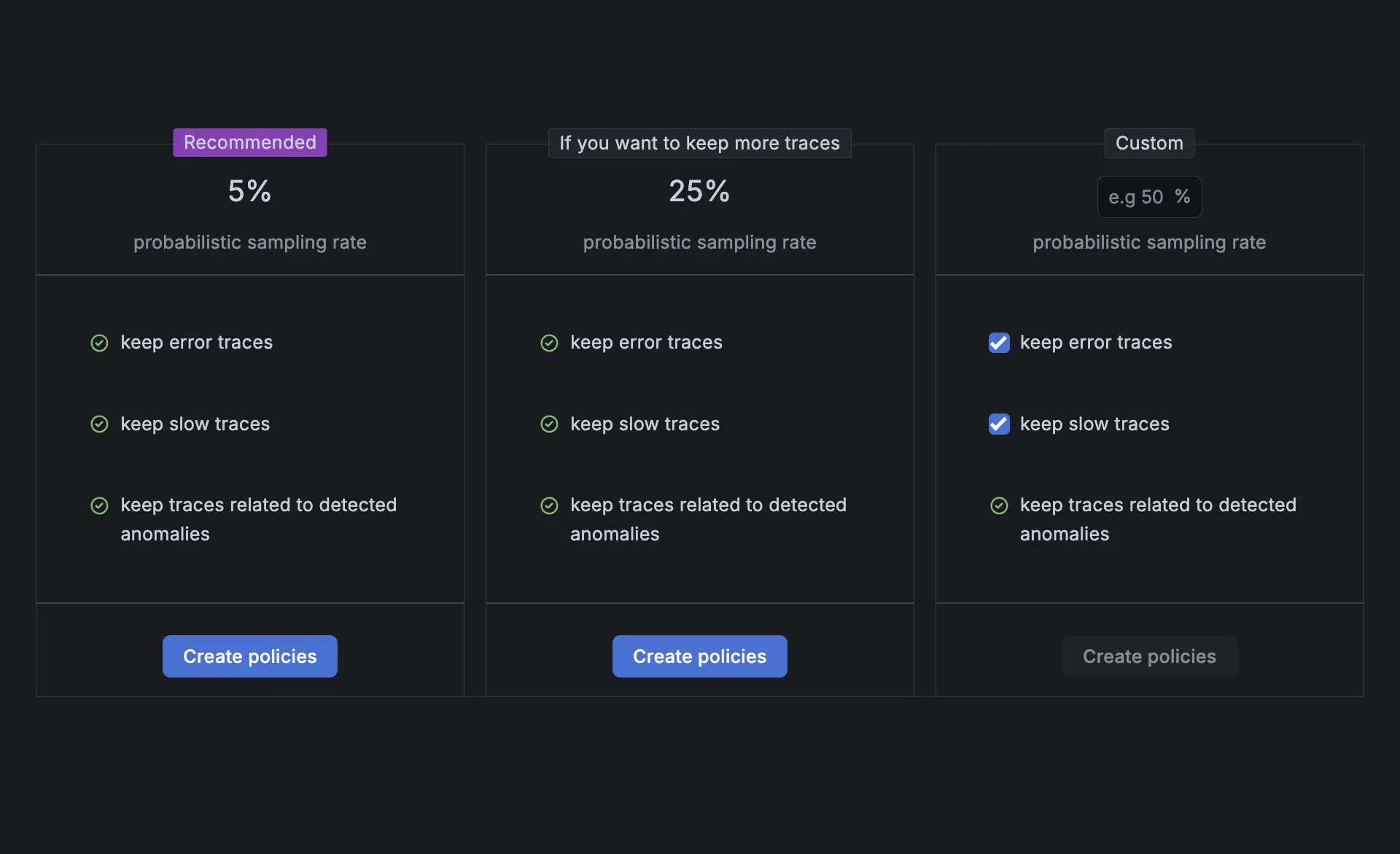
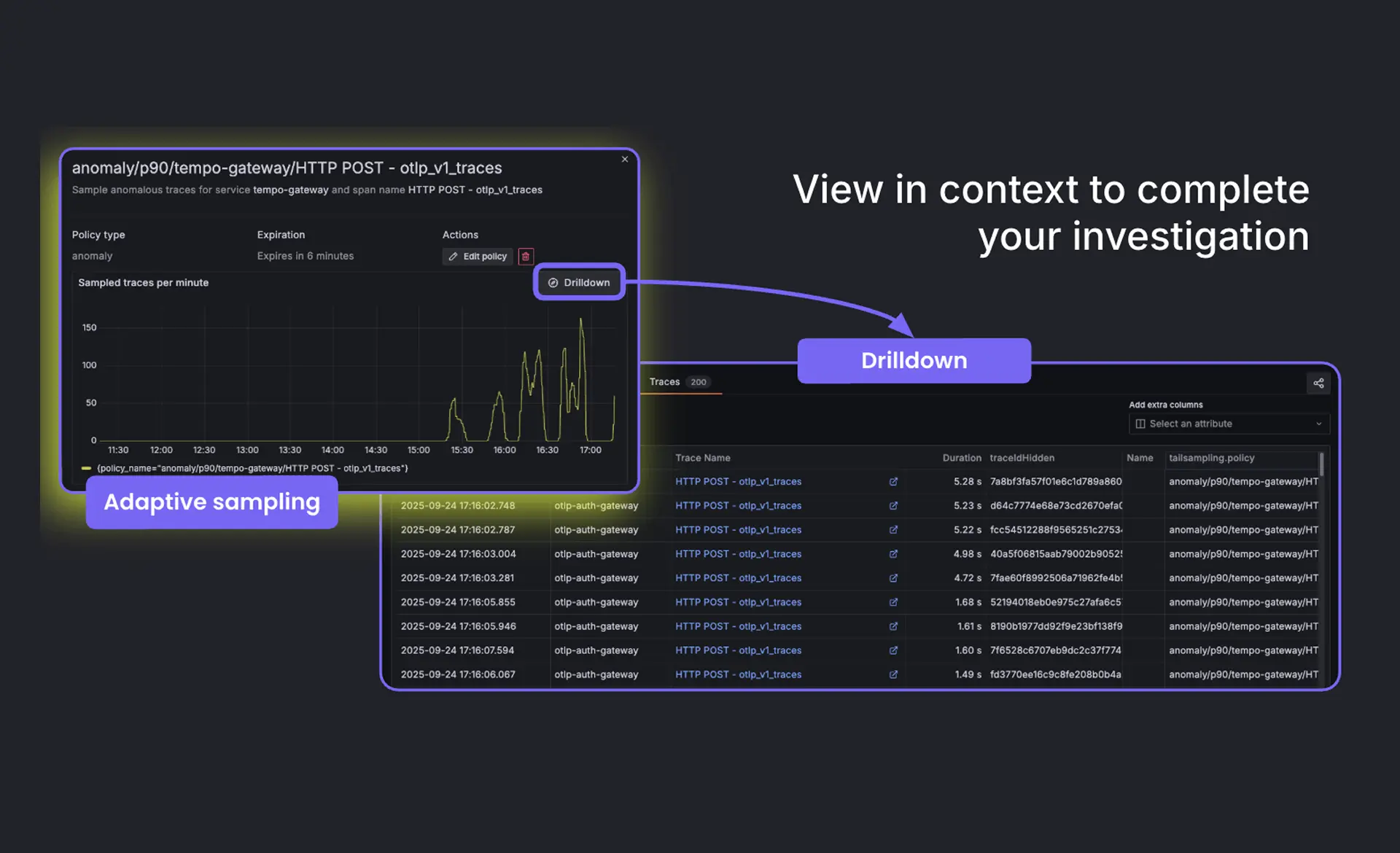
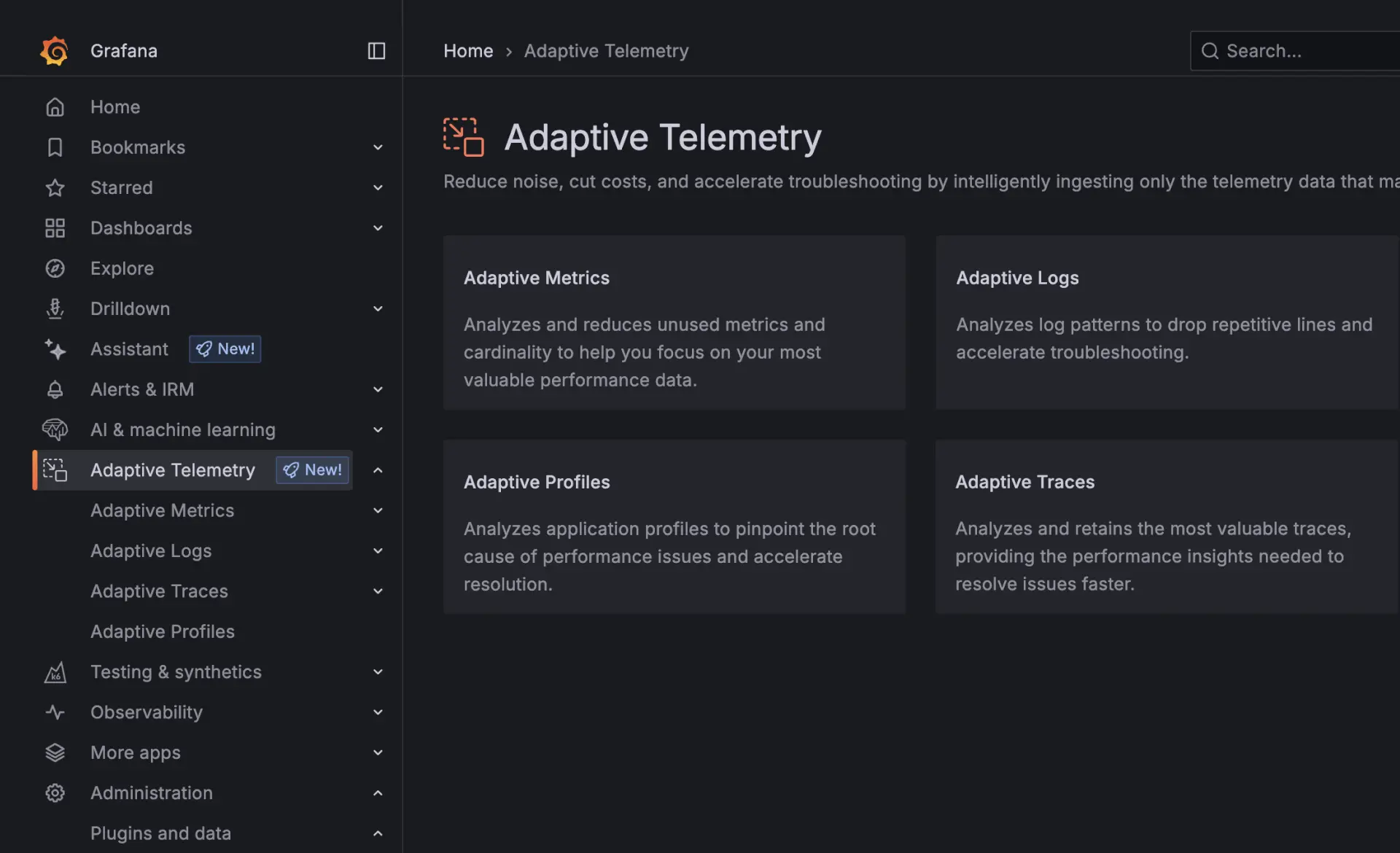
Adaptive telemetry | Richten Sie die Observability-Kosten am Nutzwert aus, indem Sie Daten mit geringem Mehrwert reduzieren und kritische Insights beibehalten.
Most organizations struggle with rapidly growing observability data that increases cost without improving insight often referred to as the observability tax. Adaptive Telemetry addresses this by analyzing how teams actually use their telemetry data and identifying signals that provide little or no value. By applying usage-based insights, it helps reduce unnecessary data volume through smarter aggregation and filtering, ensuring critical signals remain visible while minimizing noise and cost.
Bei amasol arbeiten wir eng mit Ihren Teams zusammen, um diese Empfehlungen in praktische Implementierungen innerhalb von Grafana Cloud zu überführen. Wir unterstützen Sie dabei, zu validieren, welche Daten essenziell sind, was optimiert werden kann und wie Sie die Kontrolle über Ihre Observability-Umgebung behalten, während Sie gleichzeitig die Effizienz skalierbar steigern.
Adaptive metrics
Optimiert Time-Series-Daten durch die Identifizierung und Entfernung ungenutzter oder minderwertiger Metriken mittels intelligenter Aggregation.
Adaptive logs
Reduziert Log-Volumen und Kosten durch das Filtern redundanter oder signalschwacher Log-Daten, während aussagekräftige Insights erhalten bleiben.
Adaptive traces
Sichert hochwertige Traces durch die Identifizierung relevanter Muster in Distributed-Tracing-Daten und verbessert die Performance-Sichtbarkeit, während gleichzeitig die Speicherkosten unter Kontrolle gehalten werden.
Get more information on Grafama
Sie können uns Ihre Daten hinterlassen und wir werden uns bei Ihnen melden, um einen ersten unverbindlichen Kontakt herzustellen.
Grafana blogs
Unsere Kompetenz
Profitieren Sie von über 25 Jahren fundierter Fachkompetenz und hochwertigen Dienstleistungen in unseren Kernbereichen.
Ressourcen-Center
Durchsuchen Sie unsere Ressourcenbibliothek nach Inspiration, wie amasol anderen Kunden dabei geholfen hat, ihr Experience Business voranzutreiben.
Warum amasol
Wir wollen die Flexibilität steigern, den Mehrwert erhöhen, die Effizienz der IT verbessern und so den Geschäftserfolg steigern.
Unsere Veranstaltungen
Von Expertengesprächen bis hin zu praktischen Workshops verbinden wir Strategie und Technologie.Mehr entdecken

Schenker setzt bei User Experience Monitoring und Application Performance Management im Bereich Luft- und Seefracht auf Dynatrace und amasol
Die umfassende Unterstützung von Dynatrace für moderne Cloud-, On-Premise- und Hybrid-Umgebungen stellt zudem Skalierbarkeit und langfristige Anpassungsfähigkeit sicher. Das Ergebnis ist eine zuverlässigere, kosteneffizientere und einfacher zu verwaltende Observability-Lösung im Vergleich zu fragmentierten Systemen oder weniger integrierten Ansätzen.

Dynatrace & amasol: Stronger together
85 % der Technologieführer beobachten: die zahlreichen Tools, Plattformen, Dashboards und Applikationen machen Ihr Multicloud-Environment immer komplexer.
amasol vereinfacht den Betrieb von Multicloud-Environments, verbessert die Leistung und schafft - dank unserer ganzheitlichen Lösung - einen nahtlosen Geschäftsbetrieb.
Dynatrace & amasol: Stronger together
Dynatrace bietet wertvolle Einblicke in Ihre IT-Prozesse. amasol nutzt diese Informationen und verbindet sie mit Ihren Geschäftsprozessen.
Sie haben sich erfolgreich für unsere Exeon Workbench registriert.
Guten Tag,
vielen Dank für Ihre Anmeldung zur Workbench | Bedrohungserkennung mit KI-basierter Verhaltensanalyse.
Hier sind die wichtigsten Informationen:
Wann: Dienstag, 30. September 2025 | 10:00 - 11:00 Uhr
Wo: Online via Zoom
Wir freuen uns auf Ihre Teilnahme und auf interessante Diskussionen und Präsentationen rund um das Thema Detectability.
Mit freundlichen Grüßen
Laura Ilgner
Eine Woche vor der Veranstaltung erhalten Sie von uns eine Erinnerungsmail.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.